Top 5 Python Web Scraping Tools You Need to Know in 2023
- Top 5 Python Web Scraping Tools You Need to Know in 2023
- Связанные вопросы и ответы
- Что такое веб-скрапинг и какие инструменты в Python можно использовать для этой цели
- Какие преимущества и недостатки у бесплатной версии веб-скрейпера Freemium
- Какие функции нужно учитывать при выборе среди доступных инструментов для веб-скрапинга
- Какие техники можно применять для более эффективного сбора данных с веб-сайтов
- Какие библиотеки Python можно использовать для обработки и анализа собранных веб-данных
- В чем основная разница между бесплатными и платными версиями веб-скрейперов
- Каким образом Freemium web scraper 2023 отличается от предыдущих версий
Top 5 Python Web Scraping Tools You Need to Know in 2023
Обзор лучших библиотек Python для автоматического извлечения веб-данных
Введение: Python широко известен как лучший язык программирования для начинающих из-за его высокого уровня удобочитаемости и доступности ряда библиотек и инструментов для просмотра веб-страниц. Веб-скрапинг — это процесс извлечения информации с веб-сайтов с использованием автоматизированных методов. Разработчики часто пишут поисковые роботы или скрипты для выполнения этой задачи, и Python является идеальным выбором для этого типа приложений благодаря его собственным библиотекам, специально разработанным для парсинга веб-страниц.
- ZenRows: ZenRows API — это библиотека веб-скрейпинга Python, которая обеспечивает решение некоторых наиболее распространенных проблем веб-скрейпинга, таких как анти-боты и CAPTCHA. Он прост в использовании, способен обходить CAPTCHA и антиботы, очищать страницы, обработанные JavaScript, и совместим с другими библиотеками.
- Библиотека запросов: Request — самая популярная библиотека Python для обработки HTTP-запросов, что делает ее предпочтительным выбором для многих разработчиков. Он поддерживает широкий спектр типов HTTP-запросов, предоставляя разработчикам полный контроль над заголовками и ответами. Его часто используют в сочетании с Beautiful Soup.
- LXML: эта библиотека является обновлением библиотеки запросов и обеспечивает решение проблемы, связанной с анализом HTML, связанной с библиотекой запросов. Библиотека LXML эффективна и быстра, что делает ее идеальной для извлечения больших объемов данных из HTML.
- BeautifulSoup: BeautifulSoup — это известная библиотека Python для парсинга веб-страниц как для начинающих, так и для экспертов, поскольку она удобна для пользователя и не требует беспокойства о плохом HTML. Однако он медленнее, чем LXML, поэтому рекомендуется использовать его вместе с парсером LXML.
- Scrapy: Scrapy — это платформа с открытым исходным кодом для извлечения данных с веб-сайтов. Это быстрая высокоуровневая структура, написанная на Python, которая позволяет разработчикам создавать веб-пауков для сканирования веб-сайтов и извлечения данных.
- Selenium: Selenium — это популярная библиотека очистки Python, способная очищать динамический веб-контент. Он позволяет имитировать динамические действия на веб-сайте, такие как нажатие кнопок, заполнение форм и т. д., но работает медленнее, чем другие библиотеки, и не может получать коды состояния.
- urllib3: urllib3 — это библиотека веб-скрейпинга Python, которая зависит от других библиотек, таких как экземпляр PoolManager, который обрабатывает пул соединений и безопасность потоков. Хотя он предлагает более сложный синтаксис, чем другие библиотеки, такие как Requests, он не может извлекать динамические данные.
- import.io: этот инструмент является отличным решением для автоматической проверки очищенных данных и выполнения регулярных проверок качества, чтобы избежать очистки нулевых или повторяющихся значений. Он поддерживает различные типы данных, включая сведения о продукте, рейтинги, обзоры, вопросы и ответы и доступность продукта.
- DataStreamer: DataStreamer — лучший инструмент для сбора больших объемов общедоступных данных с веб-сайтов социальных сетей. Он позволяет интегрировать неструктурированные данные в конвейер с помощью единого API и подает в конвейер более 56 000 элементов контента и 10 000 дополнений в секунду.
- Прокси-сервер: прокси-сервер не является инструментом Python, но является важным компонентом для парсинга веб-страниц. Некоторые веб-сайты не разрешают парсинг, поэтому использование прокси-сервера для маскировки вашего IP-адреса помогает избежать блокировки вашего локального IP-адреса.
Дальнейшее чтение
Дополнительные материалы на PlainEnglish.io .
Повысьте узнаваемость и признание вашего технического стартапа с помощью Circuit .
Связанные вопросы и ответы:
1. Какие основные инструменты для веб-скрапинга с использованием Python можно выделить
Для веб-скрапинга с использованием Python можно выделить такие основные инструменты, как BeautifulSoup, Scrapy, Selenium, Requests и Pandas. BeautifulSoup используется для парсинга HTML и XML документов, Scrapy - для создания веб-пауков, Selenium - для автоматизации веб-браузера, Requests - для отправки HTTP запросов, а Pandas - для обработки и анализа данных.
2. Чем отличается Freemium web scraper 2023 от других инструментов для веб-скрапинга
Freemium web scraper 2023 отличается от других инструментов для веб-скрапинга тем, что предлагает комбинацию бесплатных и платных функций. Пользователи могут использовать базовый набор возможностей бесплатно, но для расширенного функционала им придется приобрести платную подписку. Такой подход позволяет пользователям опробовать инструмент перед покупкой и выбрать наиболее подходящий тарифный план.
3. Какие преимущества использования Python для веб-скрапинга
Одним из основных преимуществ использования Python для веб-скрапинга является его простота и удобство. Синтаксис Python интуитивно понятен и позволяет писать чистый и понятный код. Кроме того, в Python существует множество библиотек и инструментов для веб-скрапинга, что делает процесс автоматизации сбора данных более эффективным.
4. Какие возможности предоставляет Freemium web scraper 2023 для пользователей
Freemium web scraper 2023 предоставляет пользователям возможность создавать и запускать веб-скраперы без необходимости написания кода. Пользователи могут настраивать параметры скрапинга, выбирать источники данных, а также сохранять и экспортировать полученные результаты в различных форматах. Кроме того, инструмент предлагает возможность мониторинга и управления скраперами через веб-интерфейс.
5. Какие сложности могут возникнуть при использовании веб-скрапинга для сбора данных
При использовании веб-скрапинга для сбора данных могут возникнуть сложности, связанные с обходом защиты от скрапинга со стороны веб-сайтов. Некоторые сайты могут блокировать IP адреса, отправляющие чрезмерное количество запросов, или использовать капчу для проверки на роботов. Кроме того, структура веб-сайтов может меняться, что потребует доработки скрапера для правильного сбора данных.
6. В чем основное преимущество использования Scrapy для веб-скрапинга
Одним из основных преимуществ использования Scrapy для веб-скрапинга является его скорость и масштабируемость. Scrapy позволяет параллельно обрабатывать несколько запросов и страниц, что делает процесс скрапинга более быстрым. Кроме того, Scrapy имеет возможность обходить AJAX контент и работать с сложными структурами веб-сайтов.
7. Какую роль играет библиотека BeautifulSoup в процессе веб-скрапинга
Библиотека BeautifulSoup играет важную роль в процессе веб-скрапинга, так как позволяет разбирать HTML и XML документы, извлекать из них нужные данные и навигироваться по структуре веб-страниц. С помощью BeautifulSoup можно находить определенные элементы на странице, извлекать текст, атрибуты и URL ссылки. Это делает процесс парсинга веб-страниц более удобным и эффективным.
8. Каким образом Freemium web scraper 2023 может повысить эффективность работы веб-скрапера
Freemium web scraper 2023 может повысить эффективность работы веб-скрапера за счет автоматизации процесса сбора данных и удобного интерфейса для настройки и мониторинга скраперов. Пользователи могут легко создавать новые скраперы, устанавливать расписание и получать уведомления о результатах через веб-интерфейс. Это позволяет сэкономить время и ресурсы при сборе и анализе данных с веб-сайтов.
Что такое веб-скрапинг и какие инструменты в Python можно использовать для этой цели
На основе данных, которые мы собираем через инструменты веб-аналитики, можно вносить корректировки на сайт и в рекламные кампании. Плюс отказываться от источников, которые приносят слишком низкую отдачу.
Вот несколько примеров того, как могут пригодиться эти данные:
● Например, мы продаём велосипеды и видим, что к нам на сайт приходит много пользователей из определённого города. После небольшого расследования становится понятно, что кроме нас в этом городе больше нет крупных магазинов, которые бы привозили велосипеды с доставкой. Это может служить сигналом к тому, чтобы сделать для этого города отдельную рекламную кампанию, и направить туда чуть больше бюджета.
● У нас есть рекламные кампании для двух городов: Москвы и Петербурга. Но из данных мы видим, что в Петербурге клиент обходится нам гораздо дешевле, чем в Москве. А средний чек при этом одинаковый. Тогда можно перераспределить бюджеты на рекламу и вливать больше денег в кампании для Петербурга.
● Вы заметили, что поведенческие факторы у людей, которые заходят на ваш сайт с ПК, гораздо лучше, чем у тех, кто сидит с мобильного. Это знак того, что нужно тщательно проверить мобильную версию сайта. Возможно, там есть какие-то недочёты, которые мешают людям полноценно пользоваться вашим ресурсом. А вы из-за этого теряете клиентов.
● У вас есть два канала продвижения: Инстаграм и Яндекс.Директ. Из Инстаграма вы получаете много посещений, но мало заявок. Из Директа посещений не так много, но зато больше людей оставляют вам свои контакты. Логично, что больше внимания и бюджета стоит уделить Яндекс.Директу.
● Вы решили проанализировать, как пользователи взаимодействуют с формой заказа, и заметили, что при заполнении одного из полей, многие люди закрывают сайт и в итоге так и не завершают заказ. Возможно, вы непонятно назвали это поле, и люди не знают, что в него вписывать. Либо пользователи считают эту информацию лишней и не готовы ей делиться. Эту причину нужно выявить и исправить. Тогда конверсия в этом месте может вырасти.
● На одном из проектов мы обнаружили большой интерес пользователей к калькулятору на статейных страницах. В структуре сайта он находился в самом низу, но при этом давал хорошие конверсии по тем людям, которые всё-таки до него добирались. На основе этих данных мы разместили его выше, плюс, добавили кнопку для перехода в него на первый экран. После этого конверсия из блога выросла на 23%.
Какие преимущества и недостатки у бесплатной версии веб-скрейпера Freemium
Большинство других библиотек Python требуют отдельного подключения. Но сделать это не сложно. При использовании современной версии Python 2.7.9 и выше или 3.4 и выше необходимый для подключения библиотек инструмент — система управления библиотекамиPIP– устанавливается автоматически. Поэтому, чтобы установить библиотеку, вам достаточно сделать всего три шага:
- Войдите в командную строку.
- На Mac OS нажмите клавиши
Command+Space, введите в появившемся окне словоTerminalи нажмитеEnter/ - На Windows нажмите клавиши
Win+R, введите в появившемся окнеcmdи нажмитеEnter.
- На Mac OS нажмите клавиши
- Чтобы проверить, установлен ли у вас
PIP, а заодно обновить его до последней версии, введите в командную строку следующие команды и нажмитеEnter:- Для Mac OS:
pip install –U pip - Для Windows:
python -m pip install -U pip
- Для Mac OS:
- Теперь просто введите
pip installи название библиотеки. Например,pip install pandasилиpip install theano, а затем нажмитеEnter. Файлы библиотеки автоматически загрузятся на компьютер, и она установится.
Узнать, какие библиотеки Python подойдут под ваши задачи, можно из этой статьи и с помощью агрегатора библиотек — pypi.org .
Разберем несколько библиотек для решения задач из разных сфер — веб-разработки, Data Science, дата-аналитики, визуализации данных и создания Telegram-ботов. Под описанием каждой библиотеки приведем код для установки.
Станьте профессиональным Python-разработчиком с нуля за 10 месяцев На Хекслете есть профессия «Python-разработчик» . Пройдите ее, чтобы изучить самый популярный язык программирования, освоить его фреймворки и создать большое портфолио с проектами на GitHub.
Какие функции нужно учитывать при выборе среди доступных инструментов для веб-скрапинга
У вебмастера, маркетолога, SEO-специалиста, специалиста по ценообразованию регулярно возникает потребность в извлечении данных со страниц сайтов в удобном для дальнейшей обработки виде. В этой статье мы разберемся, какая технология применяется для сбора данных, что это за процесс, и почему у него несколько названий.
Чаще всего в русскоязычном пространстве сбор данных со страниц веб-ресурсов принято называть парсингом ( parsing ). В англоязычном пространстве этот процесс принято называть скрейпингом (s craping).
Давайте разбираться, что это за процессы, и есть ли разница между ними.
Изначально приложение, выполняющее две операции: выкачивания нужной информации с сайта и анализа контента сайта, называлось парсингом.
В переводе с английского «parsing» — это проведение грамматического разбора слова или текста. Это производное слово от латинского «pars orationis» — часть речи.
Парсинг — это метод, при котором информация анализируется и разбивается на компоненты. Затем полученные данные преобразуются в пригодный формат для дальнейшей обработки, в процессе чего один формат данных превращается в другой, более читаемый.
Допустим, данные извлекаются в необработанном коде HTML, а парсер принимает его и преобразует в формат, который можно легко проанализировать и понять.
Парсинг использует инструментарий, который извлекает нужные значения из любых форматов данных. Извлеченные данные сохраняются в отдельном файле на компьютере/в облаке или напрямую в базе данных. Это процесс, который запускается автоматически.
Дальнейший анализ собранной информации осуществляет специальное программное обеспечение.
Что значит парсить ?
Парсер — программное решение, а парсинг — процесс. Типичный процесс парсинга сайтов состоит из следующих последовательных шагов:
‣ Идентификация целевых URL-адресов.
‣ Если веб-сайт, сканируемый для сбора данных, использует инструменты противодействия парсингу, то парсер, подбирает подходящий прокси-сервер, чтобы получить новый IP-адрес, через который отправляет свой запрос. Если необходимо, задействуется сервис разгадывания капчи.
‣ Отправка GET/POST запросов на эти URL-адреса.
‣ Поиск и обнаружение местонахождения необходимых данных в HTML-коде.
‣ Преобразование этих данных в нужный формат.
‣ Передача собранной информации в выбранное хранилище данных.
‣ Экспорт данных в нужном формате для дальнейшей работы с ними.
Со временем процесс выкачивания нужной информации с сайта и анализа контента сайта стали разделять на две самостоятельные операции. Был придуман термин краулер . Краулер занимается обходом сайта и сбором данных, а парсер анализом содержимого.
Позднее придумали термин скрейпинг. Веб-скрейпинг объединяет в себе функции краулера и парсера.
Вот какое определение веб-скрейпинга дает Википедия:
Веб-скрейпинг (или скрепинг, или скрапинг← англ. web scraping ) — это технология получения веб-данных путем извлечения их со страниц веб-ресурсов. Веб-скрейпинг может быть сделан вручную пользователем компьютера, однако термин обычно относится к автоматизированным процессам, реализованным с помощью кода, который выполняет GET-запросы на целевой сайт.
Веб-скрейпинг используется для синтаксического преобразования веб-страниц в более удобные для работы формы. Веб-страницы создаются с использованием текстовых языков разметки ( HTML и XHTML ) и содержат множество полезных данных в коде. Однако большинство веб-ресурсов предназначено для конечных пользователей, а не для удобства автоматического использования, поэтому была разработана технология, которая «очищает» веб-контент.
Но у русскоязычной аудитории термин скрейпинг/скрапинг не прижился. У нас гораздо чаще для обозначения всего процесса сбора и анализа информации используют слово парсер.
И это наглядно доказывает Яндекс Wordstat. Так по слову “парсинг” ежемесячно создается в среднем 62 тысячи запросов.
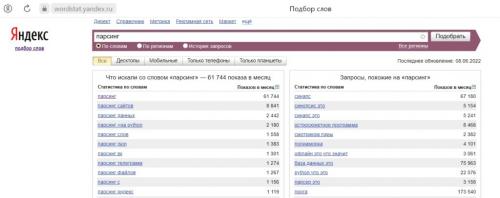
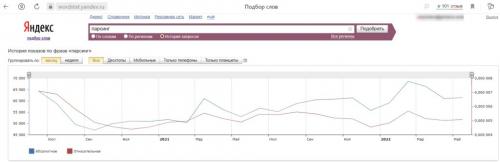
В то время как слово “скрапинг” ищут около 1300 раз в месяц, а “скрейпинг” менее 500 раз.
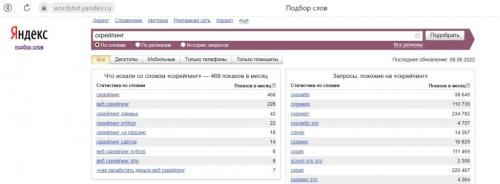
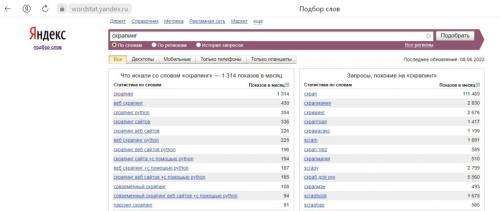
Задачи веб-скрейпинга/парсинга
Основная задача скрейпинга, это быстрое получение нужных данных из интернета с помощью специальных программ/ботов.
Большинство веб-ресурсов предназначено для конечных пользователей, а не для удобства автоматического использования, поэтому была разработана технология, которая «очищает» веб-контент и производит синтаксическое преобразование веб-страниц для последующего извлечения и анализа.
В веб-мастерстве, маркетинге, SEO и ценообразовании регулярно возникает потребность в извлечении данных со страниц сайтов в удобном для дальнейшей обработки виде. В этой статье мы рассмотрим, какие технологии используются для сбора данных, что это за процесс, и почему у него несколько названий.
Сбор данных: парсинг или скрейпинг?
Чаще всего в русскоязычном пространстве сбор данных со страниц веб-ресурсов называется парсингом (parsing), а в англоязычном пространстве - скрейпингом (scraping). Давайте разбираться, что это за процессы, и есть ли разница между ними.
История парсинга
Изначально приложение, выполняющее две операции: выкачивания нужной информации с сайта и анализа контента сайта, называлось парсингом. Перевод с английского "parsing" - это проведение грамматического разбора слова или текста. Это производное слово от латинского "pars orationis" - часть речи.
Что такое парсинг?
Парсинг - это метод, при котором информация анализируется и разбивается на компоненты. Затем полученные данные преобразуются в пригодный формат для дальнейшей обработки, в процессе чего один формат данных превращается в другой, более читаемый.
Допустим, данные извлекаются в необработанном коде HTML, а парсер принимает его и преобразует в формат, который можно легко проанализировать и понять.
Инструментарий парсинга
Парсинг использует инструментарий, который извлекает нужные значения из любых форматов данных. Извлеченные данные сохраняются в отдельном файле на компьютере/в облаке или напрямую в базе данных. Это процесс, который запускается автоматически.
Функции, которые нужно учитывать при выборе инструментов для веб-скрапинга
- Поддержка различных форматов данных (HTML, XML, JSON, CSV и т.д.)
- Возможность настройки параметров парсинга (например, выборка данных по конкретному селектору)
- Возможность автоматического запуска процесса парсинга
- Возможность сохранения данных в различных форматах (например, CSV, JSON, XML)
- Безопасность и защита от блокировки доступа к сайту
- Возможность масштабирования и использования в различных проектах
Выбор правильного инструмента для веб-скрапинга зависит от конкретных задач и требований к проекту. Важно учитывать функции, которые необходимы для успешного выполнения задачи.
Какие техники можно применять для более эффективного сбора данных с веб-сайтов
Если вы вносите изменения в порядок предоставления бесплатной версии продукта ради увеличения коэффициента конверсии, изложенная ниже информация даст вам понять, является ли имеющийся у вас уровень конверсии допустимым.
Когда респондентам задали вопрос о том, какой процент бесплатных пользователей им удается конвертировать, почти половина из них назвала цифру, лежащую в пределах от 2 до 10%, треть — 11-30%, около одной пятой — 31-50%+.
Одной из причин такого разброса в ответах может являться то, что в ходе опроса были собраны данные о трех различных типах «триала». Некоторые из респондентов имеют freemium-продукты, другие для активации пробной версии требуют данные кредитной карты, а некоторые предлагают «триал», не прося ничего взамен.
В своем посте на ресурсе Sixteen Ventures Линкольн Мерфи (Lincoln Murphy) объясняет, почему коэффициенты конверсии для разных типов пробных версий продукта могут отличаться. Мерфи говорит, что:
- уровень конверсии для freemium-продуктов, как правило, можно выразить однозначным числом;
- если вы предоставляете пробную версию, не запрашивая информацию о карте, стремитесь к показателю в 25%;
- если вы требуете предоставления платежных данных, то нацеливайтесь на уровень конверсии в 60%.
Мерфи говорит, что оптимизация для более высоких коэффициентов, чем эти ориентиры, «может привести к уменьшению отдачи от предпринятых усилий». Поэтому, если ваши коэффициенты соответствуют указанным выше значениям, дальнейшая оптимизация конверсии может и не потребоваться.
Но если это не так, то обратите внимание на советы экспертов, изложенные ниже.
Какие библиотеки Python можно использовать для обработки и анализа собранных веб-данных
Селекторы CSS - это шаблоны, используемые для выбора и нацеливания HTML-элементов веб-страницы. Они полезны для веб-скрапинга (и стилизации), поскольку обеспечивают более эффективный и целенаправленный способ получения данных из HTML-документов. Хотя можно извлекать данные непосредственно из HTML-документа с помощью различных методов, например регулярных выражений, селекторы CSS обладают рядом преимуществ, которые делают их предпочтительным выбором для веб-скрапинга.
Техники нацеливания и выбора HTML-элементов на веб-странице:
i. Выбор узла.
Выбор узла - это процесс выбора элементов HTML на основе имен их узлов. Например, выбор всех
элементы или все элементы на странице. Эта техника позволяет нацеливаться на определенные типы элементов в HTML-документе.
Пример: CSS-селектор 'h2' будет нацелен на все '
' элементов на веб-странице.
Изображение от HTML-CSS-JS
Пример из реальной жизни: Ручной поиск H2.
ii. Класс.
В CSS Selectors выбор класса подразумевает выбор HTML-элементов на основе назначенного им атрибута class. Атрибут class позволяет применить определенное имя класса к одному или нескольким элементам. Дополнительно в стилях CSS или JavaScript он может быть применен ко всем элементам с этим классом. Примерами имен "классов" являются кнопки, элементы форм, навигационные меню, макеты сетки и многое другое.
Пример: Следующий CSS-селектор: 'highlight' выберет все элементы с атрибутом class, установленным на "highlight".
В чем основная разница между бесплатными и платными версиями веб-скрейперов
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкусудобнее и лаконичнее, так что, буду использовать ее.Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого . Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении . Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут ). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Каким образом Freemium web scraper 2023 отличается от предыдущих версий
В последнее время получила распространение практика скрапинга сайтов, правомерность которой вызывает серьезные вопросы.
Скрапингом называется автоматизированный сбор информации с различных интернет-ресурсов, осуществляемый с помощью специально разработанной компьютерной программы — . Скрапинг включает в себя копирование веб-страницы в память компьютера для извлечения содержащейся в нем базовой информации. Если на исследуемом интернет-ресурсе находятся объекты авторских прав, то можно говорить о нарушении , поскольку происходит воспроизведение произведений без согласия правообладателя.
Если собираются и обобщаются данные, которые не являются объектами авторских прав, может иметь место иное нарушение — смежных исключительных прав изготовителя базы данных . В сфере смежных прав правовая охрана распространяется на объект как таковой, но не его отдельные элементы или модификации. Базы данных, для создания которых требовались существенные затраты, занимают особое место среди объектов смежных прав. П. 3 ст. 1335.1 ГК РФ устанавливает запрет на неоднократное извлечение или использование материалов, составляющих несущественную часть базы данных, если такие действия противоречат нормальному использованию базы данных и ущемляют необоснованным образом законные интересы ее изготовителя.
Американские суды склоняются к тому, что содержание коммерческих сайтов подлежит защите и скрапинг нарушает исключительные права на базу данных . При рассмотренииими была сформулирована позиция: скрапинг сайтов (в том числе данных из социальных сетей) включает копирование веб-страницы в память компьютера для извлечения с нее основной информации. Даже если копирование кратковременное, этого достаточно, чтобы образовать воспроизведение объекта авторского права согласно § 106 Закона оби, следовательно, нарушить это право.
Так, в делесуд Техаса запретил ответчику продавать программное обеспечение, которое позволяло пользователям сравнивать онлайн-тарифы авиаперевозчиков, используя данные в том числе с сайта истца. Ответчик оспорил данное решение. На стадии апелляции стороны пришли к соглашению.