10 Best Web Scraping APIs for Data Extraction.. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
- 10 Best Web Scraping APIs for Data Extraction.. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
- Free Web Scraping Tools open-source. Scrapy
- Rest api Web Scraping. A brief introduction to APIs ¶
- Instant Data scraper alternative. Что такое парсинг?
- Undetectable Web Scraping. Avoiding bot detection: How to scrape the Web without getting blocked?
- Extract Data from website to Excel free. How to Extract Structured Data from Websites to Excel in Chrome
- Octoparse Premium Pricing & Packaging
- Web Scraping api free. Octoparse - Auto-detect Supported
- How to use scraper api. Async Requests Method
10 Best Web Scraping APIs for Data Extraction.. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
13840 views
Abstract: This article will introduce the top10 best web scraping tools in 2019. They are ScrapeStorm, ScrapingHub, Import.io, Dexi.io, Diffbot, Mozenda, Parsehub, Webhose.io, Webharvy, Outwit. ScrapeStorm Free Download
Web scraping tools are designed to grab the information needed on the website. Such tools can save a lot of time for data extraction.
Here is a list of 10 recommended tools with better functionality and effectiveness.
1. ScrapeStorm
ScrapeStorm is an AI-Powered visual web scraping tool,which can be used to extract data from almost any websites without writing any code.
It is powerful and very easy to use. You only need to enter the URLs, it can intelligently identify the content and next page button, no complicated configuration, one-click scraping.
ScrapeStorm is a desktop app available for Windows, Mac, and Linux users. You can download the results in various formats including Excel, HTML, Txt and CSV. Moreover, you can export data to databases and websites.
Features:
1) Intelligent identification
2) IP Rotation and Verification Code Identification
3) Data Processing and Deduplication
4) File Download
5) Scheduled task
6) Automatic Export
8) Automatic Identification of E-commerce SKU and big images
Pros:
1) Easy to use
2) Fair price
3) Visual point and click operation
4) All systems supported
Cons:
No cloud services
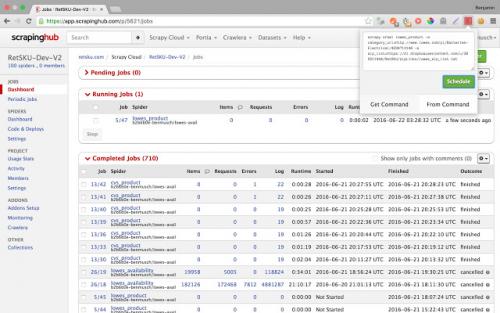
2.ScrapingHub
Scrapinghub is the developer-focused web scraping platform to offer several useful services to extract structured information from the Internet.
Scrapinghub has four major tools – Scrapy Cloud, Portia, Crawlera, and Splash.
Features:
1) Allows you to converts the entire web page into organized content
2) JS on-page support toggle
3) Handling Captchas
Pros:
1) Offer a collection of IP addresses covered more than 50 countries which is a solution for IP ban problems
2) The temporal charts were very useful
3) Handling login forms
4) The free plan retains extracted data in cloud for 7 days
Cons:
1) No Refunds
2) Not easy to use and needs to add many extensive add-ons
3) Can not process heavy sets of data
3.Import.io
Import.io is a platform which facilitates the conversion of semi-structured information in web pages into structured data, which can be used for anything from driving business decisions to integration with apps and other platforms.
They offer real-time data retrieval through their JSON REST-based and streaming APIs, and integration with many common programming languages and data analysis tools.
Features:
1) Point-and-click training
2) Automate web interaction and workflows
3) Easy Schedule data extraction
Pros:
1) Support almost every system
2) Nice clean interface and simple dashboard
3) No coding required
Cons:
1) Overpriced
2) Each sub-page costs credit
4.Dexi.io
Web Scraping & intelligent automation tool for professionals. Dexi.io is the most developed web scraping tool which enables businesses to extract and transform data from any web source through with leading automation and intelligent mining technology.
Dexi.io allows you to scrape or interact with data from any website with human precision. Advanced feature and APIs helps you transform and combine data into powerfull datasets or solutions.
Features:
1) Provide several integrations out of the box
2) Automatically de-duplicate data before sending it to your own systems.
Free Web Scraping Tools open-source. Scrapy
Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format. One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large web scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use Scrapy.
Scrapy has a couple of handy built-in export formats such as JSON, XML, and CSV. Its built for extracting specific information from websites and allows you to focus on the data extraction using CSS selectors and choosing XPath expressions. Scraping web pages using Scrapy is much faster than other open source tools so its ideal for extensive large-scale scaping. It can also be used for a wide range of purposes, from data mining to monitoring and automated testing. What stands out about Scrapy is its ease of use and . If you are familiar with Python you’ll be up and running in just a couple of minutes. It runs on Linux, Mac OS, and Windows systems.Scrapy is under BSD license.
Rest api Web Scraping. A brief introduction to APIs ¶
In this section, we will take a look at an alternative way to gather data than the previous pattern based HTML scraping. Sometimes websites offer an API (or Application Programming Interface) as a service which provides a high level interface to directly retrieve data from their repositories or databases at the backend.
From Wikipedia,
" An API is typically defined as a set of specifications, such as Hypertext Transfer Protocol (HTTP) request messages, along with a definition of the structure of response messages, usually in an Extensible Markup Language (XML) or JavaScript Object Notation (JSON) format. "
They typically tend to be URL endpoints (to be fired as requests) that need to be modified based on our requirements (what we desire in the response body) which then returns some a payload (data) within the response, formatted as either JSON, XML or HTML.
A popular web architecture style calledREST(or representational state transfer) allows users to interact with web services viaGETandPOSTcalls (two most commonly used) which we briefly saw in the previous section.
For example, Twitter's REST API allows developers to access core Twitter data and the Search API provides methods for developers to interact with Twitter Search and trends data.
There are primarily two ways to use APIs :
- Through the command terminal using URL endpoints, or
- Through programming language specific wrappers
For example,Tweepyis a famous python wrapper for Twitter API whereastwurlis a command line interface (CLI) tool but both can achieve the same outcomes.
Here we focus on the latter approach and will use a Python library (a wrapper) calledwptoolsbased around the original MediaWiki API.
One advantage of using official APIs is that they are usually compliant of the terms of service (ToS) of a particular service that researchers are looking to gather data from. However, third-party libraries or packages which claim to provide more throughput than the official APIs (rate limits, number of requests/sec) generally operate in a gray area as they tend to violate ToS. Always be sure to read their documentation throughly.
Instant Data scraper alternative. Что такое парсинг?
Парсинг — набор технологий и приемов для сбора общедоступных данных и хранения их в структурированном формате. Данные могут быть представлены множеством способов, таких как: текст, ссылки, содержимое ячеек в таблицах и так далее.
Чаще всего парсинг используется для мониторинга рыночных цен, предложений конкурентов, событий в новостных лентах, а также для составления базы данных потенциальных клиентов.
Выбор инструмента будет зависеть от множества факторов, но в первую очередь от объема добываемой информации и сложности противодействия защитным механизмам. Но всегда ли есть возможность или необходимость в привлечении специалистов? Всегда ли на сайтах встречается защита от парсинга? Может быть в каких-то случаях можно справиться самостоятельно?
Тогда что может быть сподручнее, чем всем привычный Google Chrome? !
Расширения для браузера — это хороший инструмент, если требуется собрать относительно небольшой набор данных. К тому же это рабочий способ протестировать сложность, доступность и осуществимость сбора нужных данных самостоятельно. Всё что потребуется — скачать понравившееся расширение и выбрать формат для накопления данных. Как правило это CSV (comma separated values — текстовый файл, где однотипные фрагменты разделены выбранным символом-разделителем, обычно запятой, отсюда и название) или привычные таблички Excel.
Ниже представлено сравнение десяти самых популярных расширений для Chrome.
Забегая вперед:
все платные расширения имеют некоторый бесплатный период для ознакомления;
только три — Instant Data Scraper, Spider и Scraper — полностью бесплатны;
все платные инструменты (кроме Data Miner) имеют API (Application Program Interface — программный интерфейс, который позволяет настроить совместную работу с другими программами) .
Undetectable Web Scraping. Avoiding bot detection: How to scrape the Web without getting blocked?
Whether you're just starting to build a web scraper from scratch and wondering what you're doing wrong because your solution isn't working, or you've already been working with crawlers for a while and are stuck on a page that gives you an error saying you're a bot, you can't go any further, keep reading.
Anti-bot solutions have evolved in recent years. More and more websites are introducing security measures: from simple ones, such as filtering IP addresses according to their geolocation, to advanced ones based on in-depth analysis of browser parameters and behavioral analysis. All this makes web scraping content more difficult and costly than a few years ago. Nevertheless, it is still possible. Here I highlight a few tips that you may find helpful.
Where to begin building undetectable bot?
Below you can find list of curated services that I used to get around different anti-bot protections. Depending on your use-case you may need one of the following:
| Scenario/use-case | Solution | Example |
|---|---|---|
| Short-lived sessions without auth | Pool of rotating IP addresses | That comes handy when you scrape websites like Amazon, Walmart or public LinkedIn pages. That is any website where no sign-in is required. You plan to make a high number of short-lived sessions and can afford being blocked every now and then. |
| Geographically restricted websites | Region-specific pool of IP addresses | This is useful when the website uses a firewall similar to the one from Cloudflare to block entire geography from accessing it. |
| Long-lived sessions after sign-in | Repeatable pool of IP addresses and stable set of browser fingerprints | The most common scenario here is social media automation e.g. you build a tool to automate social media accounts to manage ads more efficiently. |
| Javascript-based detection | Use of popular evasion libraries, similar to puppeteer-extra-plugin-stealth | There is a number of websites utilizing FingerprintJS that can be easily bypassed when you employ open-source plugins such as the aforementioned puppeteer stealth plugin to work with your existing software. |
| Detection with browser fingerprinting techniques | These are one of the most advanced cases. Mainstream examples are credit card processors such as Adyen or Stripe. A very sophisticated browser fingerprint is being created to detect credit fraud, or prompt additional authorization from the user. | |
| Unique set of detection techniques | Specialized bot software that targets the unique detection surface of the target website. | Good examples are sneakers marketplace websites and e-commerce shops, reportedly being under heavy attack from custom made bot software . |
| Simple custom-made detection techniques | Before diving into any of the above, if you are targeting a smaller website, it is very likely that all you need is a Scrapy script with tweaks , a cheap data-center proxy, and you are good to go. |
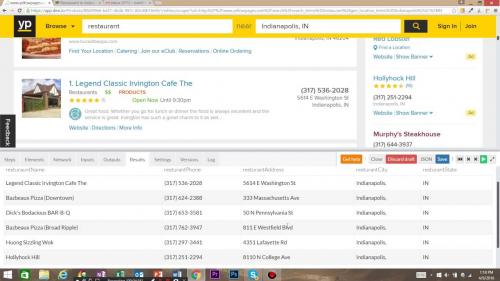
Extract Data from website to Excel free. How to Extract Structured Data from Websites to Excel in Chrome
Generally, the web scraping involves messing with webpage source code, dealing with coding, or using APIs. And still, many of these options scrape the whole web page so you end up spending time on finding the desired data elements. In this article, I covered a simple and quick method to extract selected structured data from websites.
To do that, I’m going to use, a free web scraping tool available as an extension for Google Chrome. This extension lets you choose the data elements that you want to extract and gives you a structured output. It visualizes the data on an interactive chart and lets you download the structured data in XLSX, XLS, XML, and CSV formats.
How to Extract Structured Data from a Website?
With, you can define the data elements that you want to extract from a website. You can simply select the segment by hovering the mouse cursor and label it for ease. Then, this tool collects those data elements from the similar multiple pages of that website. The free version lets you extract 1000 pages per website with no simultaneous extraction.
Data Extraction:
To extract the structured data, simply visit the webpage from where you want to extract. Wait a minute on that page and then click the Parsers icon from the menubar. This opens the Parsers overlay to define the segments which you want to extract. All you have to do is hover your cursor over the segment, and it automatically fetches that and adds that to the selected label. Then, you can enter a name for the label for easy sorting. Similarly, you can add multiple labels for different sections with the Add new Label option. After selecting the desired segments from the webpage, click the Start button from the overlay to begin the data scraping.
Data Visualization:
Once finished, this extension shows you a “ view results ” button that takes you to a new tab. In that tab, it shows you the extracted data with options to visualize each label. From here, you can download the extracted structured data as XLSX, XLS, XML, and CSV file.
Output:
The data in each format is structured as per your selection. Here is a preview of extracted structured data (XML) from this website. I added 3 labels; title, introduction, and author. This tool structured the data in that exact order from 10 pages.
Final Verdict:
Scraper Parsers is a nice tool to extract selected data from websites which can be handy for general and marketing research purposes. It gives makes the output structured so you don’t have to spend any time sorting the data. This way, you can easily extract desired data segments from various types of websites and download the catalogs of products, articles, etc. with the required characteristics.
Octoparse Premium Pricing & Packaging
5 Day Money Back Guarantee on All Octoparse Plans
- All features in Free, plus:
- 100 tasks
- Run tasks with up to 6 concurrent cloud processes
- IP rotation
- Local boost mode
- 100+ preset task templates
- IP proxies
- CAPTCHA solving
- Image & file download
- Automatic export
- Task scheduling
- API access
- Standard support
Professional Plan
Ideal for medium-sized businesses $249 / Month
when billed monthly
(OR $209/MO when billed annually) Buy Now Apply for Free Trial
- All features in Standard, plus:
- 250 tasks
- Up to 20 concurrent cloud processes
- Advanced API
- Auto backup data to cloud
- Priority support
- Task review & 1-on-1 training
Enjoy all the Pro features, plus scalable concurrent processors, multi-role access,
tailored onboarding, priority instant chat support, enterprise-level automation and
integration Simply relax and leave the work to us.
Our data team will meet with you to
discuss your web crawling and data
processing requirements.Enterprise
For businesses with high capacity
requirements Data Service
Starting from $399 Crawler Service
Starting from $250 Enterprise
Starting from $4899 / Year Data Service
Starting from $399
Web Scraping api free. Octoparse - Auto-detect Supported
Octoparse is not only a robust web scraping tool but also provides web scraping services for business owners and enterprises. Generally, the free version can meet your basic scraping needs, Or you can upgrade for advanced plans. Here are some main features you can learn from.
- Device : It can be installed on both Windows and macOS, just download and install from the Octoparse download page.
- Data : It supports almost all types of websites for scraping, including social media, e-commerce, marketing, real-estate listing, etc.
- Function :
- handle both static and dynamic websites with AJAX , JavaScript, cookies, etc.
- extract data from a complex website that requires login and pagination.
- Use Cases : As a result, you can achieve automatic inventory tracking, price monitoring, and lead generation within your fingertips.
Octoparse offers different options for users with different levels of coding skills.
- The Task Template Mode enables non-coding users to turn web pages into some structured data instantly. On average, it only takes about 6.5 seconds to pull down the data behind one page and allows you to download the data to Excel. Check out what templates are most popular .
- The Advanced mode has more flexibility. This allows users to configure and edit the workflow with more options. Advance mode is used for scraping more complex websites with a massive amount of data.
- The brand new Auto-detection feature allows you to build a crawler with one click. If you are not satisfied with the auto-generated data fields, you can always customize the scraping task to let it scrape the data for you.
- The cloud services enable large data extraction within a short time frame as multiple cloud servers concurrently are running for one task. Besides that, the cloud service will allow you to store and retrieve the data at any time.
How to use scraper api. Async Requests Method
Method #1To ensure a higher level of successful requests when using our scraper, we’ve built a new product, Async Scraper. Rather than making requests to our endpoint waiting for the response, this endpoint submits a job of scraping, in which you can later collect the data from using our status endpoint.
Scraping websites can be a difficult process; it takes numerous steps and significant effort to get through some sites’ protection which sometimes proves to be difficult with the timeout constraints of synchronous APIs. The Async Scraper will work on your requested URLs until we have achieved a 100% success rate (when applicable), returning the data to you.
Async Scraping is the recommended way to scrape pages when success rate on difficult sites is more important to you than response time (e.g. you need a set of data periodically).
How to use
The async scraper endpoint is available athttps://async.scraperapi.comand it exposes a few useful APIs.