Top 10 BEST Web Scraping proxies 2022-The Ultimate Guide. Link Assistant
- Top 10 BEST Web Scraping proxies 2022-The Ultimate Guide. Link Assistant
- Web Scraping api FREE. 20 BEST Web Scraping Tools for Data Extraction (Apr 2022 List)
- Web Scraping service. 10 FREE Web Scrapers That You Cannot Miss in 2021
- Proxy for Scraping. Benefits of using proxies for Web Scraping
- FREE Web Scraping bot. Scrapy
- Web Content Extractor Review
- Rotating proxy. What is a Rotating Proxy?
Top 10 BEST Web Scraping proxies 2022-The Ultimate Guide. Link Assistant
When it finds these sites, it builds a list and figures out how you can submit links to them, be it through contact messages, blog comments, or other contact methods. The app also stores more data than just a backlink for submission, so your links are surrounded by relevant and useful information.
This app does more than just find backlink opportunities; it uses its own internal criteria to determine just how useful those backlinks might be.
You can set it to specifically only target high-quality links, to avoid all of the spam and low quality links, if you prefer a more careful and curated route. It does this via checking domain rank, Alexa, PageRank, anchor text and social signals, among other things.
SEO Link Robot
A program with both content creation and publication features. The promotion includes social bookmark site submission, RSS submission, and curation in article databases. Content creation – not recommended – includes article spinning, posting, and so forth. It includes a captcha breaker, and some link pyramid structure settings. Uses its own database of relevant submission sites. On the other hand, it’s a little slow to use.
Money Robot Submitter
A heavy-duty automated link submission engine that has a large database of sites to submit to. These range from blogs and blog comment sections to social networks, social bookmarking sites, and forums. It also includes Wiki and various wikia sites, and articles where you can insert yourself as a relevant reference. It’s all focused on speed over outreach, though, so be wary about spam.
GScraper
This is another of the potent data harvesting tools for both white and black hat uses. It’s a very fast, very accurate Google scraper, but it absolutely requires a rotating list of proxies unless you want to be blocked for hours at a time on a regular basis. Seriously, if you have enough proxies behind it, you can scrape a million URLs in the space of 10-15 minutes. Plus it has built-in rules you can use to clean up and sort the data you harvest without having to futz with a CSV manually.
EDU Backlinks Builder
This is a smaller scale tool meant for automatically building high quality backlinks specifically from EDU domains. EDU domains do tend to have more value for Google because they’re hard to acquire and difficult to spam.
Links on them are then considered more valuable, which makes tools like this spring up to get them. Use sparingly,otherwise the abuse will be identified and you’ll lose the value you had gained.
LinkSearching
This is a web-based tool that you can use for free, which is great, because some of the tools on this list are quite expensive.
This one doesn’t really automate submission, but it is a robust scraper engine to identify relevant sites and look for link opportunities that both appear natural and pass a good deal of value. It does, however, include a database of link footprints you can use as templates to customize the anchors and submissions you do make.
BuzzStream
This is another web app that is designed as a prospect research and contact information harvesting engine. You can use it to find all the various places you might be able to submit your content, or even just comments and links.
You can then rank these sites according to your own value metrics, and send out personalized templated emails to perform some outreach. The only way it could be considered black hat is the intensity of the scraping, which can earn you a bit of a time out from Google’s web search. Proxies help here.
Integrity
Integrity and Scrutiny are two related apps you can get for various prices. Integrity for free checks links and allows you to export data on them. The plus version gives you multisite checking, searching, filtering, and XML sitemap features.
Web Scraping api FREE. 20 BEST Web Scraping Tools for Data Extraction (Apr 2022 List)
Web scraping tools are specially developed software for extracting useful information from the websites. These tools are helpful for anyone who is looking to collect some form of data from the Internet.
Here, is a curated list of Top Web Scraping Tools. This list includes commercial as well as open-source tools with popular features and latest download link.
| Scrapingbee | 1000 Free Credits + Paid Plan | Learn More |
| Bright Data | $50 credit upon depositing $50 + Paid Plan | Learn More |
| Scraper API | 1000 Free Credits + Paid Plan | Learn More |
| Apify | Free Trial + Paid Plan | Learn More |
| SCRAPEOWL | 1000 Free Credits + Paid Plan | Learn More |
| Scrapestack | Free Trial + Paid Plan | Learn More |
is a web scraping API that handles headless browsers and proxy management. It can execute Javascript on the pages and rotate proxies for each request so that you get the raw HTML page without getting blocked. They also have a dedicated API for Google search scraping
Features:
- Supports JavaScript rendering
- It provides automatic proxy rotation.
- You can directly use this application on Google Sheet.
- The application can be used with a chrome web browser.
- Great for scraping Amazon
- Support Google search scraping
is the World’s #1 Web Data platform, providing a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant. Bright Data’s next-gen Data Collector provides an automated and customized flow of data in one dashboard, no matter the size of the collection. From eCom trends and social network data to competitive intelligence and market research, data sets are tailored to your business needs. Focus on your core business by gaining access to robust data in your industry on autopilot.
Features:
- Most efficient (no-code solutions, less resources )
- Most reliable (highest quality data, better uptime, faster data, better support)
- Most flexible (premade solutions, scalable, customizable)
- Fully Compliant (transparent, reduces risk)
- 24/7 Customer Support
tool helps you to manage proxies, browsers, and CAPTCHAs. This allows you to get the HTML from any web page with a simple API call. It is easy to integrate as you just need to send a GET request to API endpoint with your API key and URL.
Features:
- Helps you to render JavaScript
- It allows you to customize the headers of each request as well as the request type
- The tool offers unparalleled speed and reliability which allows building scalable web scrapers
- Geolocated Rotating Proxies
Use coupon code “Guru” to get 10% OFF
is a web scraping and automation platform to create an API for any website, with integrated residential and data center proxies optimized for data extraction. Apify Store has ready-made scraping tools for popular websites like Instagram, Facebook, Twitter, Google Maps. Devs can earn passive income by creating tools for others, while Apify takes care of infrastructure and billing.
Features:
- Download in structured formats: JSON, XML, CSV, HTML, Excel.
- Apify Proxy: HTTPS, geolocation targeting, intelligent IP rotation, Google SERP proxies.
- Integrations: Zapier, Integromat, Keboola, Airbyte.
- Free trial: USD 5 platform credit, 30-day proxy trial.
- 20% off paid plan with GURUQ4_20OFF
software is a simple and affordable Web Scraping platform. Scrape Owl’s key focus is to scrape any data, be it e-commerce, job boards, real estate listing, etc.
Features:
- You can run custom JavaScript before content extraction.
- You can set locations to evade local limits and get local content.
- Provides a robust wait function
- It does support full-page JavaScript rendering.
- You can directly use this application on a google sheet.
- Offers a free trial for 1000 credits that can be used to test the service before buying any subscriptions. No Credit Card Required
is a real-time, web scraping REST API. Over 2,000 companies use scrapestack and trust this dedicated API backed by apilayer. The scrapestack API allows companies to scrape web pages in milliseconds, handling millions of proxy IPs, browsers & CAPTCHAs.
Web Scraping service. 10 FREE Web Scrapers That You Cannot Miss in 2021
How much do you know about? Don't worry even if you are new to this concept. As in this article, we will brief you on the basics of web scraping, teach you how to assess web scraping tools to get one that best fits your needs, and last but not least, present a list of web scraping tools for your reference.
Table of Contents
What is Web Scraping and How it is Used
Web scraping is a way of gathering data from web pages with a scraping bot, hence the whole process is done in an automated way. The technique allows people to obtain web data at a large scale fast. In the meantime, instruments like Regex () enable data cleaning during the scraping process, which means people can get well-structured clean data one-stop .
- Firstly, a web scraping bot simulates the act of human browsing the website. With the target URL entered, it sends a request to the server and gets information back in the HTML file.
- Next, with the HTML source code at hand, the bot is able to reach the node where target data lies and parse the data as it is commanded in the scraping code.
- Lastly, (based on how the scraping bot is configured) the cluster of scraped data will be cleaned, put into a structure, and ready for download or transference to your database.
How to Choose a Web Scraping Tool
There are ways to get access to web data. Even though you have narrowed it down to a web scraping tool, tools popped up in the search results with all confusing features still can make a decision hard to reach.
There are a few dimensions you may take into consideration before choosing a web scraping tool:
- Device : if you are a Mac or Linux user, you should make sure the tool support your system.
- Cloud service : cloud service is important if you want to access your data across devices anytime.
- Integration : how you would use the data later on? Integration options enable better automation of the whole process of dealing with data.
- Training : if you do not excel at programming, better make sure there are guides and support to help you throughout the data scraping journey.
- Pricing : yep, the cost of a tool shall always be taken into consideration and it varies a lot among different venders.
Now you may want to know what web scraping tools to choose from:
Three Types of Scraping Tool
- Device : As it can be installed on both Windows and Mac OS , users can scrape data with Apple devices.
- Data : Web data extraction for social media, e-commerce, marketing, real-estate listing, etc.
- Function :
- Use cases : As a result, you can achieve automatic inventories tracking, price monitoring, and leads generation within your fingertips.
There are many free . However, not all web scraping software is for non-programmers. The lists below are the best web scraping tools without coding skills at a low cost. The freeware listed below is easy to pick up and would satisfy most scraping needs with a reasonable amount of data requirement.
Web Scraping Tools Client-based
Octoparse is not only a robust web scraping tool but also provides web scraping services for business owners and enterprises. It has been extensively analyzed and approved with an independent business blog.
- handle both static and dynamic websites with AJAX , JavaScript, cookies, etc.
- extract data from a complex website that requires login and pagination.
Proxy for Scraping. Benefits of using proxies for Web Scraping
Businesses use web scraping to extract valuable data about industries and market insights in order to make data-driven decisions and offer data-powered services. Forward proxies enable businesses to scrape data effectively from various web sources.
Benefits of proxy scraping include:
Increased security
Avoid IP bans
Business websites set a limit to the amount of crawlable data called “Crawl Rate” to stop scrapers from making too many requests, hence, slowing down the website speed. Using a sufficient pool of proxies for scraping allows the crawler to get past rate limits on the target website by sending access requests from different IP addresses.
Enable access to region-specific content
Businesses who use websitemay want to monitor websites’ (e.g. competitors) offering for a specific geographical region in order to provide appropriate product features and prices. Using residential proxies with IP addresses from the targeted region allows the crawler to gain access to all the content available in that region. Additionally, requests coming from the same region look less suspicious, hence, less likely to be banned.
Enable high volume scraping
There’s no way to programmatically determine if a website is being scraped. However, the more activity a scraper has, the more likely its activity can be tracked. For example, scrapers may access the same website too quickly or at specific times every day, or reach not directly accessible webpages, which puts them at risk of being detected and banned. Proxies provide anonymity and allow making more concurrent sessions to the same or different websites.
FREE Web Scraping bot. Scrapy
Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format. One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large web scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use Scrapy.
Scrapy has a couple of handy built-in export formats such as JSON, XML, and CSV. Its built for extracting specific information from websites and allows you to focus on the data extraction using CSS selectors and choosing XPath expressions. Scraping web pages using Scrapy is much faster than other open source tools so its ideal for extensive large-scale scaping. It can also be used for a wide range of purposes, from data mining to monitoring and automated testing. What stands out about Scrapy is its ease of use and . If you are familiar with Python you’ll be up and running in just a couple of minutes. It runs on Linux, Mac OS, and Windows systems.Scrapy is under BSD license.
Web Content Extractor Review
Web Content Extractor is a visual user-oriented tool that scrapes typical pages. Its simplicity makes for a quick start up in data ripping .
Overview
Web Content Extractor (WCE) is a simple user-oriented application that scrapes web pages and parses data from them. This program is easy to use, but it gives you the ability to save every single project for future (daily) use. The trial version will work with only 150 records per scrape project. As far as exporting and putting data into different formats, Web Content Extractor is excellent for grouping data into Excel, text, HTML formats, MS Access DB, SQL Script File, MySQL Script File, XML file, HTTP submit form and ODBC Data source. Being a simple and user friendly application, it steadily grows in practical functionality for complex scrape cases.
Workflow
Let’s see how to scrape data from londonstockexchange.com using Web Content Extractor. First, you need to open the starting page in the internal browser:
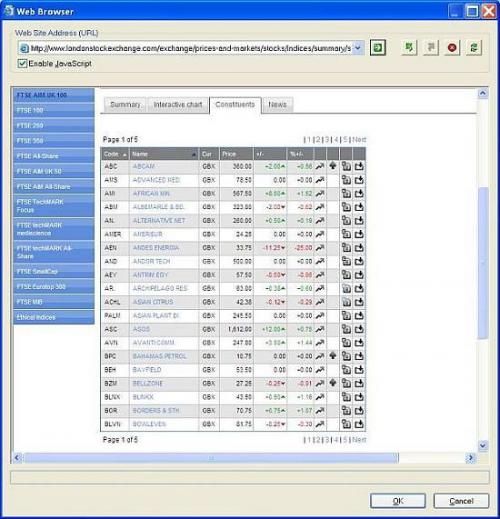
Then, you need to define “crawling rules” in order to iterate through all the records in the stock table:
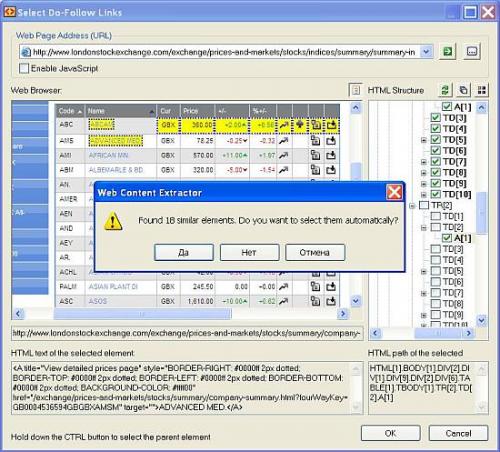
Also, as you need to process all the pages, set the scraper to follow the “Next” link on every page:
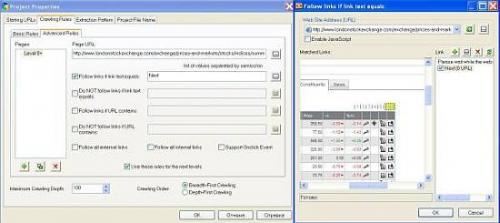
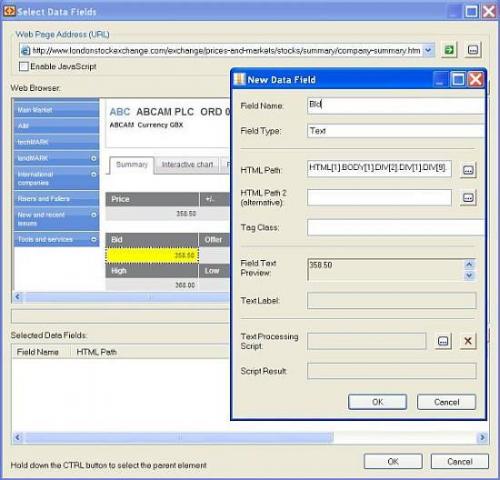
And finally, when you’re done with all the rules and patterns, run the web scraping session. You may track the scraped data at the bottom:
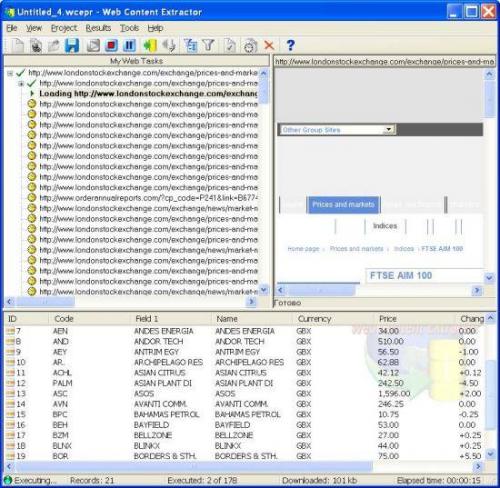
As soon as you get all the web data scraped, export it into the desired destination:
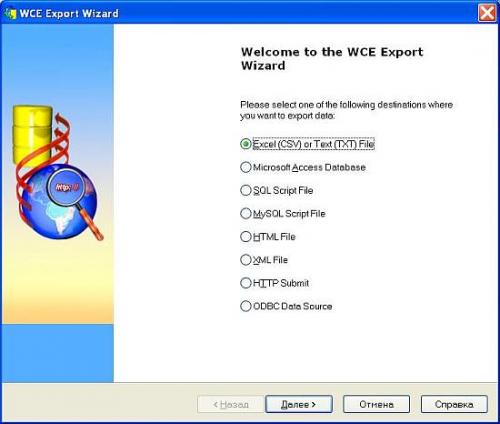
Dynamic Elements Extraction
Scraping of dynamic web page elements (like popups and ajax-driven web snippets) is not an easy task. Originally, we didn’t consider Web Content Extractor to be able to break through here, but with transformation URL script, it’s possible. Thanks to the Newprosoft support center, we got help with crawling over popups on a certain web page.
Go to Project->Properties->Crawling Rules->URL Transformation Script, where you may compose a script that will change casual crawl behavior into a customized one:
The task of building a transformation script is not a trivial one. Yes, it is possible to make a project to crawl through dynamic elements, but, practically speaking, you’ll need to know web programming ( XPath , Regex , JavaScript, VBScript, jQuery).
Here is an example of such an URL transformation script for scraping popups from http://www.fox.com/schedule/ (the script was composed by a Newprosoft specialist, so in difficult cases you’ll need to turn to them):
Function Main ( strText ) dim strResult If ( InStr ( strText, "episode" ) > 0 ) Then strjQueryValue = Get_jQueryValue ( strText ) If ( IsNumeric( strjQueryValue ) ) Then strResult = "javascript: jQuery('div.episode:eq(" + CStr ( CInt ( strjQueryValue ) - 2 ) + ")').mouseenter(); void(0);" End If End If Main = strResult End Function Function Get_jQueryValue ( strText ) dim strResult strResult = Sub_String ( strText , " jQuery" , ">" , "") strResult = Sub_String ( strResult , "=""" , """" , "") Get_jQueryValue = strResult End Function Function Sub_String ( strText , strStartSearchFor , strEndSearchFor , strReverseSearch ) dim numStartPos , numEndPos , numLineIndex, strResult If ( Len ( strStartSearchFor ) > 0 ) Then If ( strReverseSearch = "1" ) Then numStartPos = InStrRev ( strText , strStartSearchFor ) Else numStartPos = InStr ( strText , strStartSearchFor ) End If Else numStartPos = 1 End If If ( Len ( strEndSearchFor ) > 0 ) Then numEndPos = InStr ( numStartPos + Len( strStartSearchFor ) , strText , strEndSearchFor ) Else numEndPos = Len ( strText ) + 1 End If If ( numEndPos = 0 ) Then strEndSearchFor = "" numEndPos = Len ( strText ) + 1 End If If ( numStartPos > 0 AND numEndPos > numStartPos + Len ( strStartSearchFor ) ) Then strResult = Mid ( strText , numStartPos + Len ( strStartSearchFor ) , numEndPos - numStartPos - Len ( strStartSearchFor ) ) Else strResult = "" End If Sub_String = strResult End Function
Multi-Threading and More
As far as multi-threading, the Web Content Extractor sends several server requests at the same time (up to 20), but remember that each session runs with only one extraction pattern. Filtering helps with sifting through the results.
Summary
The Web Content Extractor is a tool to get the data you need in “5 clicks” (the example task we completed within 15 minutes). It works well if you scrape simple pages with minimum complications for your private or small enterprise purposes.
Rotating proxy. What is a Rotating Proxy?
A rotating proxy is a proxy server that automatically rotates your requests amongst a massive IP proxy pool every time the you make a new connection to the proxy server. Using this approach, you don’t need to build and maintain your own proxy rotation infrastructure on your end. Instead, you can just send your requests to the proxy server and it will use a different proxy with every request. Ensuring that you aren’t constantly using the same proxies to make requests to the target website.
Using a rotating proxy like this makes it easier to simulate many different users connecting to an online service or website instead of multiple requests from a single user. Enabling you to bypass even relatively advanced anti-bot systems and still get the successful responses you need to scrape your target data. And even if one IP does get blocked, your next connection request will have a different IP and most likely will be successful.
The rotating proxy technique can be implemented with both dedicated/datacenter proxies as well as residential proxies. Although the latter will be even more effective, using rotating proxies with either will dramatically increase your success rate when running web scraping, or other similar, tools.
If you are looking for a rotating proxy solution then be sure to give ScraperAPI a try by signing up to a free trial with 5,000 free requests . Not only is ScraperAPI a rotating proxy solution that automatically rotates your requests amongst a proxy pool with over 40M proxies, it also automatically uses the best header configuration for your target website and handles all bans and CAPTCHAs thrown by a sites anti-bot system.