Using proxies for web scraping. What is web scraping with proxies?
- Using proxies for web scraping. What is web scraping with proxies?
- Bridge Data proxy. Bright Data Overview
- Web scraping what is it. What is web scraping?
- Web scraping API. What is API Web Scraping (How Does it Work?)
- Python proxy https. Как использовать прокси в Requests
- Python proxies for scraping. The ultimate guide for using proxies for Web Scraping with Python Posted at
- VPN for web scraping. Scrape hidden Data from complex & protected website — Opera VPN my precious
Using proxies for web scraping. What is web scraping with proxies?
Scraping the web is an increasingly important procedure used to gather various kinds of useful information from the web. It is a technique employed to extract large amounts of data from different websites, followed by the data’s extraction to a local file in your computer or a designated database.
With a sizable explosion of the worldwide web and an increasing digitization of everyday tasks, scraping for the information is a go-to activity when it comes to acquiring business intelligence data, price comparisons, knowledge of how specific target groups are feeling about a brand or a product and much more.
For example, imagine that you are looking forward to acquire a brand new laptop for yourself. Understandably, you will feel inclined to get the best bargain possible,and that’s where web scraping comes to help. Running a price comparison procedure consists of a few basic steps:
- The first thing that we will have to do is to find the URL that we’d want to scrape ( i.e. an URL generated after entering “Thinkpad” into an Amazon search bar).
- As we already have our target URL, it is time to inspect this particular page to find out where exactly price information is being stored on the sitemap. You can do that by marking the price tag on the page, right clicking on it and selecting “Inspect”.
- Okay, so now we have opened the targeted website’s sitemap. The highlighted area in the HTML code is where pricing information is located.
- Now, there’s a handful of ways on how you can scrape this data. You can use Python or Javascript commands if you have some basic coding skills. If that is not the case, specialized scraping software exists where you can just simply copy/paste the class parameters that contains the pricing information and start scraping with a click of a button.
- The last step is storing the data. If you are using a scraping software, it will let you select the place where you’d like to store the file. Storing them on an Excel sheet works just fine for that.
Bridge Data proxy. Bright Data Overview
Bearing in mind that Bright Data is wider scope, it is classified according to its proxy types. First, there are residential proxy IPs given to residents by their ISP (Internet Service Provider.) Bright Data proxies are one of the greatest offerings over 72 million IPs. They also have mobile proxies and datacenter proxies that emanate from mobile providers and ISP providers, respectively.
We have it on good authority that their annual turnover exceeds $100 million. And now, they are pivoting more towards the sourcing of datasets, which is a cost-effective way, so they have gone from strength to strength.
Bright Data Specifications
| IP Pool | 72+ million | IP Type | Residential/ Datacenter/Mobile |
| Price Sample | 40 GB – $500 (Monthly) | Price Charged | Bandwidth |
| Proxy Protocol | HTTP(S)/Socks5 | Authentication | User Pass /IP Auth |
| Free trial | 7 days | Refund policy | Not support |
| Geo-targeting | ASN/Cites/Countries | Jurisdiction | Israel |
Bright Data Types
As we have said earlier, there are various Bright Data proxy categories. These categories depend on the source of the provider. The most common Luminosity types include datacenter proxies, mobile proxies, and residential proxies.

First, the residential proxies represent its greatest offering with over 72 million IPs. You can either have Bright Data's static residential proxies or rotation proxies. With static, you possess fixed IPs in multiple countries. For the rotating proxies, they can change and acquire new IPs.
Then there are the datacenter proxies with over 770,000 proxies. Datacenters proxies have no ISP tag as residential ones, but their servers come from cloud platforms or other remote servers. Typically, you share the datacenter proxies when using the same cloud source.
If your concern is about a mobile proxy that supports a SIM's 3G, 4G, or the new 5G, Bright Data's mobile proxy is your answer. Bright Data's mobile proxy contains around seven million IPs and optimizes ASN and carrier targeting.
Bright Data Pricing
Bright Data offers different pricing rates that you should consider before buying their package. Typically, Bright Data proxies are expensive for personal use, but as you know, ‘quality comes at a cost.' For instance, $300 or $1000 monthly can be the cheapest value in Bright Data proxy, which can go up to $30000 per month on an enterprise basis. And now they have added a “pay as you go” plan, that makes it available to more people.
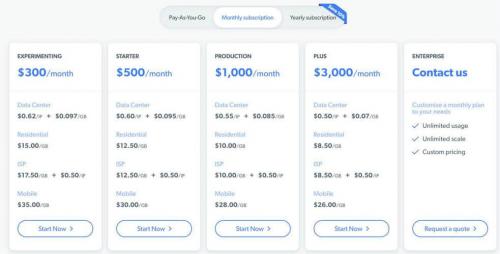
The Bright Data pricing depends on the proxy type you choose and the bandwidth for each plan. The bandwidth is scaled in terms of gigabytes or GB. The higher the bandwidth, the more expensive a proxy IP costs.
When it comes to residential, datacenter, mobile, or static residential proxies, they have different rates. Of those categories, datacenter proxies are the cheapest as they cost less than a dollar, while mobile proxies are expensive at $15/Gb.
Regarding the Bright Data offer period, you would expect a yearly plan to be more expensive than a monthly or ‘pay as you go’ offer. Suppose you don't have money when a premium period expires, you can still use the proxy by changing it to a ‘pay as you go' offer.
Bright Data Authentication
You cannot solely depend on Bright Data’s encrypted HTTPS, SOCKS5, and other Bright Data's in-house technology for data security. Some hackers or trackers can get past these secure protocols, but they cannot bypass your Bright Data username and passwords.
When you register to your Bright Data account, the system will ask you for your preferred password and username. Usually, Bright Data requires you to provide a strong password of lengthy characters and mixed letters. In other cases, the system can autogenerate for you a password.
There is also IP whitelisting, which is another authentication protocol in Bright Data. IP whitelisting means filtering IPs and remaining with IP types connected to a trusted website.
Bright Data Protocols
Thanks to HTTPS, HTTP, and SOCKS5 protocols, Bright Data is one of the world's most secure proxies. Most importantly, the SOCKS5 Bright Data's protocol is more secure because it has an advanced authentication level. Still, this proxy is lightweight and utilizes a tunneling method for HTTP and FTP support; no wonder it is used in Bright Data Proxy Manager.
On the other hand, there are HTTP and HTTPS Bright Data proxies. Both of these protocols work in generating leads for Bright Data residential proxies. If you wonder how Bright Data accelerates, compresses, or manages its vast IPs, it is because of its HTTPS and HTTP protocols.
Additionally, you do not configure proxies’ protocols when using Bright Data Proxy Manager (LPM). That is, every port in Bright Data identifies SOCK5, HTTP, and HTTPS. When you create a SOCKS5 connection, it automatically changes to HTTP or HTTPS.
Web scraping what is it. What is web scraping?
Web scraping is a technique for targeted, automated extraction of information from websites .
Similar extraction can be done manually but it is usually faster, more efficient and less error-prone to automate the task.
Web scraping allows you to acquire non-tabular or poorly structured data from websites and convert it into a usable, structured format, such as a .csv file or spreadsheet.
Scraping is about more than just acquiring data: it can also help you archive data and track changes to data online.
For example:
- Online stores will periodically scour the publicly available pages of their competitors, scrape item names and prices and then use this information to adjust their own prices.
- collecting online article comments and other discourse for analysis (e.g. using text mining)
- gathering data on membership and activity of online organisations
- collecting archives of reports from many web pages
- telling a computer how to navigate through a web site to find required content (sometimes called spidering ); and
- providing patterns with which the computer can identify and extract required content.
- Data downloads : some web sites provide their content in structured forms. Some names for data formats include Excel, CSV, RSS, XML and JSON.
- APIs: many major sources and distributors of content provide software developers with a web-based Application Programming Interface to query and download their often dynamic data in a structured format. APIs tend to differ from each other in design, so some new development tends to be required to get data from each one. Most require some authentication like a username and password before access is granted (even when it is granted for free).
- semantic web knowledge bases : web sites providing structured knowledge, of which WikiData is a good example. These tend to be structured as OWL ontologies, and can often be queried through SPARQL endpoints or downloaded as large data collections.
- microformats : some web sites may overlay their visual content with specially schematised labels for certain kinds of knowledge, such as publication metadata (title, author, publication date), contact details or product reviews. While web sites using microformats are by far in the minority, where they are, specialised extraction tools do not need to be developed.
Applications of scraping in research and journalism may include:
The practice of data journalism , in particular, relies on the ability of investigative journalists to harvest data that is not always presented or published in a form that allows analysis.
Behind the web’s facade
At the heart of the problem which web scraping solves is that the web is (mostly) designed for humans. Very often, web sites are built to display structured content which is stored in a database on a web server. Yet they tend to provide content in a way that loads quickly, is useful for someone with a mouse or a touchscreen, and looks good. They format the structured content with templates, surround it with boilerplate content like headers, make parts of it shown or hidden with the click of a mouse. Such presentation is often called unstructured .
In other cases, the data presented in a web site has been edited or collated manually, and does not present some underlying structured database.
Web scraping aims to transform specific content in a web site into a structured form: a database, a spreadsheet, an XML representation, etc.
Web designers expect that readers will interpret the content by using prior knowledge of what a header looks like, what a menu looks like, what a next page link looks like, what a person’s name, a location, an email address. Computers do not have this intuition.
Web scraping therefore involves:
Not web scraping: structured content on the web
There are, however, many forms of structured content on the web, which are (ideally) already machine-readable (although they may still need transformation to fit into your database/format of choice). These include:
Web scraping API. What is API Web Scraping (How Does it Work?)
 Let’s say you’re on Amazon and you want to download a list of certain products and their prices to better tailor your business strategy. You have two options: first, you could use the same format the website you’re viewing uses, or two, you could manually copy and paste the information you need into a spreadsheet. If both of those options sound daunting and like a lot of work, you’re right. Fortunately, web scraping can make this process easier.
Let’s say you’re on Amazon and you want to download a list of certain products and their prices to better tailor your business strategy. You have two options: first, you could use the same format the website you’re viewing uses, or two, you could manually copy and paste the information you need into a spreadsheet. If both of those options sound daunting and like a lot of work, you’re right. Fortunately, web scraping can make this process easier.
In short, a web scraper API is the perfect solution for any developer, digital marketer, or small business leader who is looking for a programmatic way to scrape data without any need to worry about the management of scraping servers and proxies. An API will handle all of the obscure processing stuff for you and simply funnel scraped data into your existing software programs and processes. From there, you can do whatever further data processing you need. An API can drive data-driven insights in limitless ways. Treat data as a valuable resource, use the right tools to optimize that collection process, and then you can use its value to guide your processes in whatever direction you need.
What is web scraping?
Web scraping is the process of extracting large amounts of data into a spreadsheet or another format of your choosing. In order to scrape a website, you’ll pick a URL (or several) that you want to extract data from and load it into the web scraper. Once this URL is entered, the web scraper will load the HTML code, allowing you to customize what type of data you’d like to be extracted.
For example, let’s say you sell camping gear and you want to extract all of the products and their prices from your competitor’s website for the same kind of products but you want to omit the excess information like reviews and other information you don’t need. All you’d have to do is filter out what you don’t want to be included and the web scraper will compile a list containing only the information you need. This is where API comes in.
What is API?
Application programming interface (commonly abbreviated as API) allows two different types of programs to talk to one another. An API is a computing interface that simplifies interactions between different pieces of software you use APIs every single day. Chatting with someone through social media and even checking your daily email on your iPhone are both common examples of how an API works. In the case of our web scraping API, you can use a piece of software to send a request to our API endpoint and execute a web scraping command, as defined in the documentation . Users can submit a web scraping request and get the data they need immediately – 60 seconds to be exact – and have it organized and downloaded in their preferred format, all of which is done in real-time.
Python proxy https. Как использовать прокси в Requests
- Чтобы использовать прокси в Python, сначала импортируйте пакет requests.
- Далее создайте словарь
proxies, определяющий HTTP и HTTPS соединения. Эта переменная должна быть словарем, который сопоставляет протокол с URL прокси. Кроме того, создайте переменную url, содержащую веб-страницу, с которой вы собираетесь делать скрейпинг.
Обратите внимание, что в приведенном ниже примере словарь определяет URL прокси для двух отдельных протоколов: HTTP и HTTPS. Каждое соединение соответствует отдельному URL и порту, но это не означает, что они не могут быть одинаковыми
Наконец, создайте переменную ответа, которая использует любой из методов запроса. Метод будет принимать два аргумента: созданную вами переменную URL и определенный словарь с proxy.
Вы можете использовать один и тот же синтаксис для разных вызовов api, но независимо от того, какой вызов вы делаете, вам необходимо указать протокол.
Python proxies for scraping. The ultimate guide for using proxies for Web Scraping with Python Posted at
Python is a high-level programming language that is used for web development, mobile application development, and also for scraping the web.
Python is considered as the finest programming language for web scraping because it can handle all the crawling processes smoothly. When you combine the capabilities of Python with the security of a web proxy , then you can perform all your scraping activities smoothly without the fear of IP banning.
In this article, you will understand how proxies are used for web scraping with Python. But, first, let’s understand the basics.
WHAT IS WEB SCRAPING?
Web scraping works by first crawling the URLs and then downloading the page data one by one. All the extracted data is stored in a spreadsheet. You save tons of time when you automate the process of copying and pasting data. You can easily extract data from thousands of URLs based on your requirement to stay ahead of your competitors.
EXAMPLE OF WEB SCRAPING
An example of a web scraping would be to download a list of all pet parents in California. You can scrape a web directory that lists the name and email ids of people in California who own a pet. You can use web scraping software to do this task for you. The software will crawl all the required URLs and then extract the required data. The extracted data will be kept in a spreadsheet.
WHY USE A PROXY FOR WEB SCRAPING?
- Proxy lets you bypass any content related geo-restrictions because you can choose a location of your choice.
- You can place a high number of connection requests without getting banned.
- It increases the speed with which you request and copy data because any issues related to your ISP slowing down your internet speed is reduced.
- Your crawling program can smoothly run and download the data without the risk of getting blocked.
Now that you have understood the basics of web scraping and proxies. Let’s learn how you can perform web scraping using a proxy with the Python programming language.

VPN for web scraping. Scrape hidden Data from complex & protected website — Opera VPN my precious
To build a data science project, we first need data. In many use cases, the data comes from internal relational or non-relational databases. But, the best way to get massive free data collection is to use Crawling/Scraping techniques. Of course, in the last ten years of scraping, companies have updated the way they protect their data and it can be very difficult today to collect data from some websites.
Even though the task is more complex, some of us continue to do it and try to elevate it to an art form. The latest case studies have focused on LinkedIn and Facebook in particular, where, using advanced scraping techniques, they have managed to collect more than 70% of all the data they have.
In this article, we will see the use of Opera VPN, to bypass complex geolocation restrictions when scraping a website.
Disclaimer: this informations on this article is provided for education and informational purpose only. Please note that the information provided on this page is for information purposes only and does not constitute professional legal advice on the practice of web scraping. If you are concerned about the legal implications of using web scraping on a project you are working on, it is probably a good idea to seek advice from a professional, preferably someone who has knowledge of the intellectual property (copyright) legislation in effect in your country. Selenium supports automation of all the major browsers in the market through the use of WebDriver .