Top 10 Web Scraping Tools and Software Compared. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
13.09.2023 в 15:44
Содержание
- Top 10 Web Scraping Tools and Software Compared. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
- Scraping python library. Beautiful Soup
- Data Scraping. Automated Data Scraping with Tools
- United Lead scraper Crack. Guru Lead Crusher Cracked Email Extractor – Free Download Crack
- Scrapy. Introducing Scrapy
- Video scraper. Vget for YouTube:
- How to get Data from website. 16 Tools to extract Data from website
Top 10 Web Scraping Tools and Software Compared. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
14607 views
Abstract: This article will introduce the top10 best web scraping tools in 2019. They are ScrapeStorm, ScrapingHub, Import.io, Dexi.io, Diffbot, Mozenda, Parsehub, Webhose.io, Webharvy, Outwit. ScrapeStorm Free Download
Web scraping tools are designed to grab the information needed on the website. Such tools can save a lot of time for data extraction.
Here is a list of 10 recommended tools with better functionality and effectiveness.
1. ScrapeStorm
ScrapeStorm is an AI-Powered visual web scraping tool,which can be used to extract data from almost any websites without writing any code.
It is powerful and very easy to use. You only need to enter the URLs, it can intelligently identify the content and next page button, no complicated configuration, one-click scraping.
ScrapeStorm is a desktop app available for Windows, Mac, and Linux users. You can download the results in various formats including Excel, HTML, Txt and CSV. Moreover, you can export data to databases and websites.
Features:
1) Intelligent identification
2) IP Rotation and Verification Code Identification
3) Data Processing and Deduplication
4) File Download
5) Scheduled task
6) Automatic Export
8) Automatic Identification of E-commerce SKU and big images
Pros:
1) Easy to use
2) Fair price
3) Visual point and click operation
4) All systems supported
Cons:
No cloud services
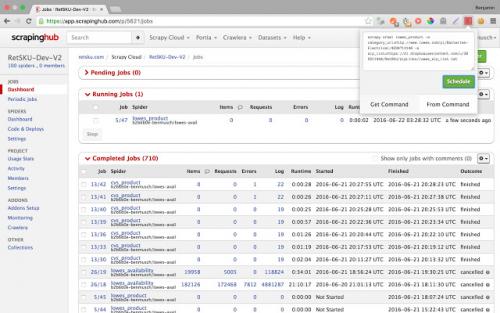
2.ScrapingHub
Scrapinghub is the developer-focused web scraping platform to offer several useful services to extract structured information from the Internet.
Scrapinghub has four major tools – Scrapy Cloud, Portia, Crawlera, and Splash.
Features:
1) Allows you to converts the entire web page into organized content
2) JS on-page support toggle
3) Handling Captchas
Pros:
1) Offer a collection of IP addresses covered more than 50 countries which is a solution for IP ban problems
2) The temporal charts were very useful
3) Handling login forms
4) The free plan retains extracted data in cloud for 7 days
Cons:
1) No Refunds
2) Not easy to use and needs to add many extensive add-ons
3) Can not process heavy sets of data
3.Import.io
Import.io is a platform which facilitates the conversion of semi-structured information in web pages into structured data, which can be used for anything from driving business decisions to integration with apps and other platforms.
They offer real-time data retrieval through their JSON REST-based and streaming APIs, and integration with many common programming languages and data analysis tools.
Features:
1) Point-and-click training
2) Automate web interaction and workflows
3) Easy Schedule data extraction
Pros:
1) Support almost every system
2) Nice clean interface and simple dashboard
3) No coding required
Cons:
1) Overpriced
2) Each sub-page costs credit
4.Dexi.io
Web Scraping & intelligent automation tool for professionals. Dexi.io is the most developed web scraping tool which enables businesses to extract and transform data from any web source through with leading automation and intelligent mining technology.
Dexi.io allows you to scrape or interact with data from any website with human precision. Advanced feature and APIs helps you transform and combine data into powerfull datasets or solutions.
Features:
1) Provide several integrations out of the box
2) Automatically de-duplicate data before sending it to your own systems.
Scraping python library. Beautiful Soup
Beautiful Soup is one of the best Python libraries for parsing HTML and XML documents. It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping. It is also used to extract data from some JavaScript-based web pages.
Open your terminal and run the command below:
pip install beautifulsoup4
With Beautiful Soup installed, create a new Python file, name it beautiful_soup.py
We are going to scrape (Books to Scrape) website for demonstration purposes. The Books to Scrape website looks like this:
We want to extract the titles of each book and display them on the terminal. The first step in scraping a website is understanding its HTML layout. In this case, you can view the HTML layout of this page by right-clicking on the page, above the first book in the list. Then click Inspect .
Below is a screenshot showing the inspected HTML elements.
You can see that the list is inside the
- element. The next direct child is the
- element.
What we want is the book title, which is inside the , inside the
, inside the
, and finally inside the - element.
To scrape and get the book title, let’s create a new Python file and call it beautiful_soup.py
When done, add the following code to the beautiful_soup.py file:
from urllib.request import urlopen from bs4 import BeautifulSoup url_to_scrape = request_page = urlopen(url_to_scrape) page_html = request_page.read() request_page.close() html_soup = BeautifulSoup(page_html, ‘html.parser’) for data in html_soup.select(‘ol’): for title in data.find_all(‘a’): print(title.get_text())
In the above code snippet, we open our webpage with the help of the urlopen() method. The read() method reads the whole page and assigns the contents to the page_html variable. We then parse the page using html.parser to help us understand HTML code in a nested fashion.
- element. We loop through the HTML elements inside the
- element to get the tags which contain the book names. Finally, we print out each text inside the tags on every loop it runs with the help of the get_text() method.
python beautiful_soup.py
This should display something like this:
Now let’s get the prices of the books too.
tag, inside a
tag. As you can see there is more than onetag and more than one
tag. To get the right element with the book price, we will use CSS class selectors; lucky for us; each class is unique for each tag.
Data Scraping. Automated Data Scraping with Tools
Getting to grips with using dynamic web queries in Excel is a useful way to gain an understanding of data scraping. However, if you intend to use data regularly scraping in your work, you may find a dedicated data scraping tool more effective.
Here are our thoughts on a few of the most popular data scraping tools on the market:
Data Scraper (Chrome plugin)
Data Scraper slots straight into your Chrome browser extensions, allowing you to choose from a range of ready-made data scraping “recipes” to extract data from whichever web page is loaded in your browser.
This tool works especially well with popular data scraping sources like Twitter and Wikipedia, as the plugin includes a greater variety of recipe options for such sites.
As you can see, the tool has provided a table with the username of every account which had posted recently on the hashtag, plus their tweet and its URL
Having this data in this format would be more useful to a PR rep than simply seeing the data in Twitter’s browser view for a number of reasons:
- It could be used to help create a database of press contacts
- You could keep referring back to this list and easily find what you’re looking for, whereas Twitter continuously updates
- The list is sortable and editable
- It gives you ownership of the data – which could be taken offline or changed at any moment
We’re impressed with Data Scraper, even though its public recipes are sometimes slightly rough-around-the-edges. Try installing the free version on Chrome, and have a play around with extracting data. Be sure to watch the intro movie they provide to get an idea of how the tool works and some simple ways to extract the data you want.
Getting to grips with using dynamic web queries in Excel is a useful way to gain an understanding of data scraping. However, if you intend to use data regularly scraping in your work, you may find a dedicated data scraping tool more effective.
A Few Popular Data Scraping Tools
This article will explore a few of the most popular data scraping tools on the market:
- Data Scraper: This tool works especially well with popular data scraping sources like Twitter and Wikipedia, as the plugin includes a greater variety of recipe options for such sites.
- Oxylers: This tool is great for extracting data from websites with complex structures, such as those with multiple pages or forms.
- : This tool offers a range of features, including the ability to extract data from websites, create datasets, and even perform data analysis.
Data Scraper Example
Let's take a look at an example of how Data Scraper can be used:
| Username | Tweet | URL |
|---|---|---|
| JohnDoe | This is a sample tweet | https://twitter.com/JohnDoe/status/1234567890 |
| JaneSmith | This is another sample tweet | https://twitter.com/JaneSmith/status/2345678901 |
Having this data in this format would be more useful to a PR rep than simply seeing the data in Twitter's browser view for a number of reasons:
- It's easier to analyze and sort the data
- It's easier to share the data with others
- It's easier to use the data for further analysis or reporting
We're impressed with Data Scraper, even though its public recipes are sometimes slightly rough-around-the-edges. Try installing the free version on Chrome, and have a play around with extracting data. Be sure to watch the intro movie they provide to get an idea of how the tool works and some simple ways to extract the data you want.
WebHarvy
WebHarvy is a point-and-click data scraper with a free trial version. Its biggest selling point is its flexibility – you can use the tool’s in-built web browser to navigate to the data you would like to import, and can then create your own mining specifications to extract exactly what you need from the source website.
import.io
Import.io is a feature-rich data mining tool suite that does much of the hard work for you. Has some interesting features, including “What’s changed?” reports that can notify you of updates to specified websites – ideal for in-depth competitor analysis.
United Lead scraper Crack. Guru Lead Crusher Cracked Email Extractor – Free Download Crack
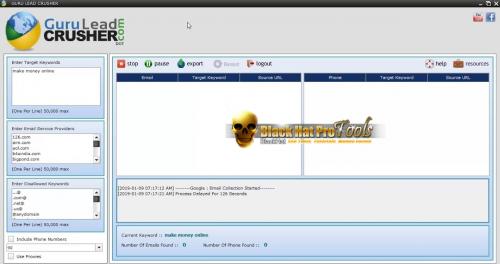
Guru Lead Crusher Email Extractor Cracked – Free Download Crack
A SMALL PROGRAM DELIVERING BIG RESULTS!The easiest lead scraper to use that collects up to 400% more valuable and targeted emails.
PRODUCES RESULTS
WATCH HOW THE GURU CAN BENEFIT YOUThese videos show how the Guru Lead Crusher can be used to target a country, company or market.
TARGET A COUNTRY
TARGET A COMPANY
TARGET A MARKET
TARGET ANY KEYWORD
TYPE ONE WORD, CLICK ONE BUTTON AND THE GURU WILL DELIVER RESULTS
If you market a product, service or opportunity online then you need leads, and lots of them. You know the value of targeted leads, leads that are responsive to your offer. It’s a no-brainer, get the Guru Lead Crusher today.
HERE’S WHY THE GURU IS AWESOME!
Programs can be full of bells and whistles that you will never use, like the 38 cup holders in my Honda Odyssey. It sounded cool when I bought it but after 5 years I have only used 2 of them. While our software should be priced higher our philosophy is, make it very effective, as simple as possible and affordable for the masses.
VERY EFFECTIVESee for yourself, download the trial version and discover how many leads you can find. We have tested it against a number of scrapers and the Guru discovers as many as 400% more leads. The technology also makes sure the data is clean.
SIMPLE AS POSSIBLEWe have used a lot of scrapers and they are good… but… they can be hard to figure out or require your personal attention to work properly. The Guru is as simple as 3 steps to use and get fantastic results.
AFFORDABLEDuring our beta testing it was recommended that we charge at least $297! That is not our philosophy and it was decided we would make it affordable to the masses knowing there are marketers all over the world that need this tool.
THE GURU’S AWESOME FEATURES
MAC AND WINDOWS COMPATIBLEWe are very happy to say that Mac users don’t have to be left out in the cold. This may not seem important to window users but a lot of programs are still windows only. We know how important it is for a Mac user to be able to use a tool like this and have made sure you can get all the power of the Guru.
SUPER EASY TO USEYou literally type one or more keywords and click start. That is no exaggeration. We provide tutorial videos to walk you through using the Guru to be more targeted in your marketing. You will be able to target countries, companies, companies in countries and just about anything you can think of, cool, right?
USES FEW COMPUTER RESOURCESA lot of scrapers slow down your entire computer because of the poorly written code. Many people stop using them as a result of getting so frustrated by not being able to open a browser window at the same time. The Guru code is clean and efficient making it hardly noticeable when you are trying to use your computer for other things at the same time.
EASY LEAD EXPORTINGClick one button when the program is done processing your keyword(s) and save the universally recognized CSV file to your computer. This CSV file will be easy to use with any email service.
TARGETING FILTERSYou can add up to 50,000 email providers or remove them depending on the data you desire to obtain. There is also a disallow keyword filter so you can prevent getting emails that you don’t want. This allows you to do serious targeting for lead demographics that you desire. Tutorial videos are available to walk you through using the program in a more advanced method.
AUTOMATIONWhile there are a couple steps you have to do manually, most of the work is done automatically by the Guru. This saves you time to do the things you want or need to do. Time is money and the Guru will virtually put money in your pocket every time you start it up and put it to work for you.
QUERY DELAYUse a simple drop down menu to determine how many seconds you want the Guru to pause before it continues to work. The easiest is to leave the delay set to random so it works naturally.
PROXIES (NOT REQUIRED)We have included proxy integration for free or paid proxies. This is an optional setting and is not required to get lots of benefits from the Guru.
DEATHBYCAPTCHA (NOT REQUIRED)You can use DeathByCaptcha for those instances when you are doing a lot of work and you need to answer a human verification question to continue working. It is best to use proxies at the same time.
Scrapy. Introducing Scrapy
A framework is a reusable, “semi-complete” application that can be specialized to produce custom applications. (Source: Johnson & Foote, 1988 )
In other words, the Scrapy framework provides a set of Python scripts that contain most of the code required to use Python for web scraping. We need only to add the last bit of code required to tell Python what pages to visit, what information to extract from those pages, and what to do with it. Scrapy also comes with a set of scripts to setup a new project and to control the scrapers that we will create.
It also means that Scrapy doesn’t work on its own. It requires a working Python installation (Python 2.7 and higher or 3.4 and higher - it should work in both Python 2 and 3), and a series of libraries to work. If you haven’t installed Python or Scrapy on your machine, you can refer to the setup instructions . If you install Scrapy as suggested there, it should take care to install all required libraries as well.
scrapy version
in a shell. If all is good, you should get the following back (as of February 2017):
Scrapy 2.1.0
If you have a newer version, you should be fine as well.
To introduce the use of Scrapy, we will reuse the same example we used in the previous section. We will start by scraping a list of URLs from the list of faculty of the Psychological & Brain Sciences and then visit those URLs to scrape detailed information about those faculty members.
Video scraper. Vget for YouTube:
Although there are loads of plugins for Chrome browser you can use to download videos from YouTube, like this one saveFrom Hleper which I’m using. It’s quite versatile, not only for YouTube,but also for any online video-site else and quite well get along with the browser. Just like this:
Two new buttons attached on the page. However, the shortage is that you have to manually download the videos one by one. If you want to download a channel’s all videos the arduous work emerged. ———– What I want it is using the YouTube API to retrieve all the videos’ address and input them into program and analysis their addresses and download. After searching in Google, I found Vget Home which is what I want. You can read through examples list on that page. Essentially, this lib using YouTubeParser.java to extract video link via matching regex.
How to get Data from website. 16 Tools to extract Data from website
In today's business world, smart data-driven decisions are the number one priority. For this reason, companies track, monitor, and record information 24/7. The good news is there is plenty of public data on servers that can help businesses stay competitive.
The process of extracting data from web pages manually can be tiring, time-consuming, error-prone, and sometimes even impossible. That is why most web data analysis efforts use automated tools.
Web scraping is an automated method of collecting data from web pages. Data is extracted from web pages using software called web scrapers, which are basically web bots.
What is data extraction, and how does it work?
Data extraction or web scraping pursues a task to extract information from a source, process, and filter it to be later used for strategy building and decision-making. It may be part of digital marketing efforts, data science, and data analytics. The extracted data goes through the ETL process (extract, transform, load) and is then used for business intelligence (BI). This field is complicated, multi-layered, and informative. Everything starts with web scraping and the tactics on how it is extracted effectively.
Before automation tools, data extraction was performed at the code level, but it was not practical for day-to-day data scraping. Today, there are no-code or low-code robust data extraction tools that make the whole process significantly easier.
What are the use cases for data extraction?
To help data extraction meet business objectives, the extracted data needs to be used for a given purpose. The common use cases for web scraping may include but are not limited to:
- Online price monitoring: to dynamically change pricing and stay competitive.
- Real estate: data for building real-estate listings.
- News aggregation: as an alternative data for finance/hedge funds.
- Social media: scraping to get insights and metrics for social media strategy.
- Review aggregation: scraping gathers reviews from predefined brand and reputation management sources.
- Lead generation: the list of target websites is scraped to collect contact information.
- Search engine results: to support SEO strategy and monitor SERP.
Is it legal to extract data from websites?
Web scraping has become the primary method for typical data collection, but is it legal to use the data? There is no definite answer and strict regulation, but data extraction may be considered illegal if you use non-public information. Every tip described below targets publicly available data which is legal to extract. However, it is still illegal is to use the scrapped data for commercial purposes.
How to extract data from a website
Manually extracting data from a website (copy/pasting information to a spreadsheet) is time-consuming and difficult when dealing with big data. If the company has in-house developers, it is possible to build a web scraping pipeline. There are several ways of manual web scraping.
1. Code a web scraper with Python
It is possible to quickly build software with any general-purpose programming language like Java, JavaScript, PHP, C, C#, and so on. Nevertheless, Python is the top choice because of its simplicity and availability of libraries for developing a web scraper.
2. Use a data service
Data service is a professional web service providing research and data extraction according to business requirements. Similar services may be a good option if there is a budget for data extraction.
3. Use Excel for data extraction
This method may surprise you, but Microsoft Excel software can be a useful tool for data manipulation. With web scraping, you can easily get information saved in an excel sheet. The only problem is that this method can be used for extracting tables only.
4. Web scraping tools
Modern data extraction tools are the top robust no-code/low code solutions to support business processes. With three types of data extraction tools – batch processing, open-source, and cloud-based tools – you can create a cycle of web scraping and data analysis. So, let's review the best tools available on the market.