Что такое парсер и нюансы его использования. Собственные внутриорганизационные решения
- Что такое парсер и нюансы его использования. Собственные внутриорганизационные решения
- Что такое парсинг сайтов. Парсинг: что это такое простыми словами
- Что такое парсинг в программировании. Пример парсера для Инстаграм
- Парсинг данных. Для чего парсинг нужен?
- Парсер сайтов в excel. Проблема с нетабличными данными
- Парсинг python. Инструменты
- Парсинг это простыми словами. Что такое парсинг
- Парсинг сайтов python. Часть 1
Что такое парсер и нюансы его использования. Собственные внутриорганизационные решения
Используя готовое существующее программное обеспечение (ПО) с открытым или закрытым исходным кодом и навыки программирования, любая компания может создавать качественные парсеры веб-сайтов. При условии, что у компании есть технический персонал для осуществления этой задачи, и что парсинг необходим для реализации стратегически важного проекта, собственную разработку можно считать оптимальным вариантом.
Выбор подходящего инструмента или веб-сервиса для сбора данных во Всемирной паутине зависит от различных факторов, включая тип проекта, бюджет и наличие технического персонала. Чтобы кратко охарактеризовать представленную выше схему принятия решения, правильный ход мыслей при выборе автоматического сборщика данных должен быть таким:
- Собираетесь ли вы собирать данные только для личного использования? Если да, то выберите инструмент с открытым исходным кодом или его community-версию, что позволит вам собирать данные бесплатно.
- Если нет, то работает ли ваша IT-компания над стратегически важными проектами, которые дифференцируют ваши продукты или услуг?
- Если да, то сформируйте в компании команду, которая будет предотвращать сбор ваших данных сторонними компаниями.
- Если нет, то позволяет ли ваш бюджет инвестировать более $10 000?
- Если да, то отдайте предпочтение управляемым услугам, поскольку системы парсинга данных требуют существенных усилий по их поддержке. Возможно, что вам не захочется, чтобы команда вашей компании была сосредоточена на поддержке проекта, который не является стратегически важным.
- Если нет, то есть ли у вас навыки программирования? Если есть, то отдайте предпочтение решениям с открытым исходным кодом или недорогим проприетарным решениям. Разработка своего парсера может быть эффективнее, чем использование решений, не требующих написания программного кода, поскольку разработанное решение может предложить более высокий уровень автоматизации.
- Если их нет, то сделайте выбор в пользу решений, которыми можно пользоваться без программирования. Большинство из них проприетарные, но их можно приобрести и с ограниченным бюджетом.
Что такое парсинг сайтов. Парсинг: что это такое простыми словами
Сегодня парсинг настолько распространен, что о нем должен знать каждый вебмастер, а маркетолог и подавно. Когда-нибудь его надо включать в список обязательных инструментов, ведь при грамотном использовании можно извлечь немало пользы. Процесс этот отличается от взлома, а если следовать инструкциям (прописанным в robots.txt на сайтах), то и вполне законный.

Что такое парсинг и что значит парсить
Дословный перевод слова parsing — делать грамматический разбор или структурировать. В программировании/информатике, это автоматический сбор и систематизация необходимых сведений, размещенных на веб-ресурсах с помощью специальных программ.
Принцип работы парсинга основывается на сравнении готового общепринятого шаблона и найденной в сети информации. Например, вы создали интернет-магазин и хотите его продвигать. Вам нужно скопировать данные о товарах (цены, изображения, описания) у конкурентов, а потом разместить на своем сайте. Делать это вручную — длительная и рутинная работа, особенно когда речь идет о 500-1000 товарах. Поэтому процесс автоматизируется, и сбор данных доверяется программе/сервису. Результатом станет колоссальная экономия времени.
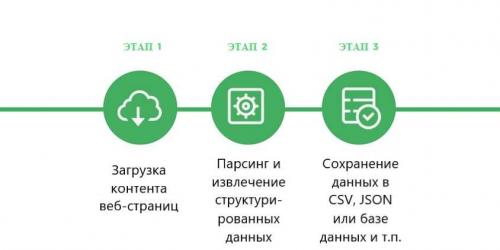
Подробнее о преимуществах автоматического сбора данных:
- высокая скорость получения информации — очевидный факт, так как все компьютерные технологии в обработке данных превосходят ручной сбор;
- точное структурирование по определенному критерию — отчет можно получать в виде чистых цифр, адресов, описаний, картинок и т. д (смотря, как настроить);
- отсутствие ошибок — вычислительной машине не свойственно уставать и ошибаться из-за невнимательности;
- удобный формат получения информации — XLSX, CSV, XML, JSON и даже сразу выгрузка на сайт;
- равномерное распределение нагрузки на анализируемую страницу — таким образом, сводится на нет противозаконная атака DDOS.
Единственное, что не умеет делать парсер, это уникализировать информацию — контент просто собирается из открытых источников.
Программа парсер
В роли парсера может выступить программа, сервис или скрипт. Функция у них одна — собрать данные с указанных web-сайтов, анализировать и выдать в нужном формате. Обычно используют десктопные и облачные парсеры, основное преимущество которых в отсутствии необходимости скачивать программу и устанавливать на свой комп. Вся работа производится в облаке.
Вот, например, несколько облачных парсеров на русском языке.
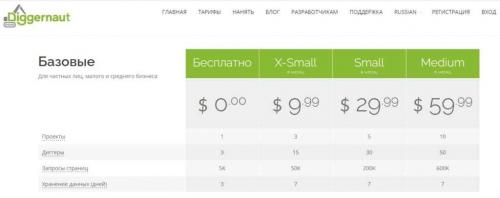
- Диггернаут. Облачный сервис, робот которого умеет добывать открытую информацию — цены и отзывы о товарах, данные для статистического исследования, сводка из государственных/муниципальных источников и многое другое. На сайте действует бесплатный и платный тарифы.
- Xmldatafeed. Способен ежедневно парсить ведущие сайты Рунета, анализировать и мониторить цены конкурентов. Готовые каталоги можно скачивать бесплатно.
- Catalogloader. Аналогичный сервис, предлагающий эффективные решения для онлайн-бизнеса. Умеет обрабатывать прайсы поставщиков/интернет-магазинов и выгружать таблицы с ценами (все это бесплатно).

А это пара десктопных сервисов:
- ParserOK — можно скачать демо-версию и проверить, а затем купить лицензию на продукт с полным функционалом на 2 компьютера или больше;
- Key Collector;
- Словоеб;
- Rush Analytics;
- Магадан;
- Moab и другие.
- подготавливается список товаров;
- задается автоматический поиск по составленному каталогу;
- готовые данные (описание, иллюстрации) выгружаются на сайт заказчика.
Что такое парсинг слов и зачем нужно
Парсинг также активно применяется вебмастерами и оптимизаторами для сбора семантического ядра с дальнейшей кластеризацией запросов. Таким образом, инструмент может решить вопросы с продвижением сайта и составлением рекламной кампании в Яндекс.Директе и Гугл Адс.
Среди популярных программ для парсинга в Seo:
В этапы работ над семантическим ядром сайта входит — определение поисковых фраз, анализ конкурентов, сбор данных со всех источников и т. д.
Что такое парсинг товаров и зачем нужно
Парсить товары, значит — собирать нужную информацию о продукции из готового каталога онлайн-магазинов. Обычно это делается в целях анализа ценовой политики конкурентов или для заполнения витрины своих сайтов. Ручной сбор такой информации и тщательная сортировка занимает много времени, поэтому автоматизация процесса напрашивается априори.
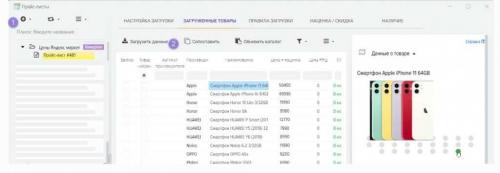
Например, парсинг товаров часто используется владельцами крупных интернет-магазинов. Это позволяет избавиться от рутинной работы, увеличить скорость сбора данных и сделать процесс более качественным.
Вот как работает парсинг:
Что такое парсинг в программировании. Пример парсера для Инстаграм
Очень часто вижу запросы «пример парсера для инстаграм» или «пример парсера для социальных сетей», поэтому давайте разберемся что значит парсер для социальных сетей, групп и аккаунтов?
Если проще, то парсер для соц сетей — это помощник, который способствует продвижению товаров и услуг. То есть, такой парсер позволяет собрать данные пользователей, которые они указывают в своих аккаунтах или группах/пабликах (ну и прочую инфу) и в дальнейшем выборочно показывать им рекламу.
У Instagram как раз есть есть своя молодая, активная и платежеспособная аудитория, на которую хотят повлиять рекламодатели, поэтому давайте чуть подробнее остановимся на этой соц сети.
Парсинг данных. Для чего парсинг нужен?
В первую очередь, целью парсинга является ценовая «разведка», ассортиментный анализ, отслеживание товарных акций. “Кто, что, за сколько и в каких количествах продаёт?” – основные вопросы, на которые парсинг должен ответить. Если говорить более подробно, то парсинг ассортимента конкурентов или того же Яндекс.Маркет отвечает на первые три вопроса.С оборотом товара несколько сложней. Однако, такие компании как “Wildberries”, “Lamoda“ и Леруа Мерлен, открыто предоставляют информацию об ежедневных объемах продаж (заказах) или остатках товара, на основе которой не сложно составить общее представлении о продажах (часто слышу мнение, мол эти данные могут искажаться намеренно — возможно, а возможно и нет). Смотрим, сколько было товара на складе сегодня, завтра, послезавтра и так в течении месяца и вот уже готов график и динамика изменения количества по позиции составлена (оборачиваемость товара фактически). Чем выше динамика, тем больше оборот. Потенциально возможный способ узнать оборачиваемость товаров с помощью ежедневного анализа остатков сайта Леруа Мерлен. Можно, конечно, сослаться на перемещение товаров между точками. Но суммарно, если брать, например, Москву — то число не сильно изменится, а в существенные передвижения товара по регионам верится с трудом.С объемами продаж ситуация аналогична. Есть, конечно, компании, которые публикуют информацию в виде много/мало, но даже с этим можно работать, и самые продаваемые позиции легко отслеживаются. Особенно, если отсечь дешёвые позиции и сфокусироваться исключительно на тех, что представляют наибольшую ценность. По крайней мере, мы такой анализ делали – интересно получалось.Во-вторых, парсинг используется для получения контента. Здесь уже могут иметь место истории в стиле “правовых оттенков серого”. Многие зацикливаются на том, что парсинг – это именно воровство контента, хотя это совершенно не так. Парсинг – это всего лишь автоматизированный сбор информации, не более того. Например, парсинг фотографий, особенно с “водяными знаками” – это чистой воды воровство контента и нарушение авторских прав. Потому таким обычно не занимаются (мы в своей работе ограничиваемся сбором ссылок на изображения, не более того… ну иногда просят посчитать количество фотографий, отследить наличие видео на товар и дать ссылку и т.п.).Касательно сбора контента, интересней ситуация с описаниями товаров. Недавно нам поступил заказ на сбор данных по 50 сайтам крупных онлайн-аптек. Помимо информации об ассортименте и цене, нас попросили “спарсить” описание лекарственных аппаратов – то самое, что вложено в каждую пачку и является т.н. фактической информацией, т.е. маловероятно попадает под закон о защите авторских прав. В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов. Но да, могут быть и авторские описания лекарств, которые заверены у нотариуса и сделаны специально как своего рода ловушки для воришек контента :).Рассмотрим также сбор описания книг, например, с ОЗОН.РУ или Лабиринт.ру. Здесь уже ситуация не так однозначна с правовой точки зрения. С одной стороны, использование такого описания может нарушать авторское право, особенно если описание каждой карточки с товаром было нотариально заверено (в чём я сильно сомневаюсь — ведь может и не быть заверено, исключение — небольшие ресурсы, которые хотят затаскать по судам воров контента). В любом случае, в данной ситуации придётся сильно «попотеть», чтобы доказать уникальность этого описания. Некоторые клиенты идут еще дальше — подключают синонимайзеры, которые «на лету» меняют (хорошо или плохо) слова в описании, сохраняя общий смысл.Ещё одно из применений парсинга довольно оригинально – “самопарсинг”. Здесь преследуется несколько целей. Для начала – это отслеживание того, что происходит с наполнением сайта: где битые ссылки, где описания не хватает, дублирование товаров, отсутствие иллюстраций и т.д. Полчаса работы парсера — и вот у тебя готовая таблица со всеми категориями и данными. Удобно! “Самопарсинг” можно использовать и для того, чтобы сравнить остатки на сайте со своими складскими остатками (есть и такие заказчики, отслеживают сбои выгрузок на сайт). Ещё одно применение “самопарсинга”, с которым мы столкнулись в работе — это структурирование данных с сайта для выгрузки их на Яндекс Маркет. Ребятам так проще было сделать, чем вручную этим заниматься.Также парсятся объявления, например, на ЦИАН-е, Авито и т.д. Цели тут могут быть как перепродажи баз риелторам или туроператорам, так и откровенный телефонный спам, ретаргетинг и т.п. В случае с Авито это особенно явно, т.к. сразу составляется таблица с телефонами пользователей (несмотря на то, что Авито подменяет телефоны пользователей для защиты и публикует их в виде изображения, от поступающих звонков все равно никуда не уйти).
Парсер сайтов в excel. Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data - From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ ) и нажать ОК :
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора :
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные ) или сразу на лист Excel (кнопка Загрузить ).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию - считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query "не видит" таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом
Парсинг python. Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкусудобнее и лаконичнее, так что, буду использовать ее.Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого . Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении . Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут ). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Парсинг это простыми словами. Что такое парсинг
Парсинг — это процесс автоматического сбора данных и их структурирования.
Специальные программы или сервисы-парсеры «обходят» сайт и собирают данные, которые соответствуют заданному условию.
Простой пример: допустим, нужно собрать контакты потенциальных партнеров из определенной ниши. Вы можете это сделать вручную. Надо будет заходить на каждый сайт, искать раздел «Контакты», копировать в отдельную таблицу телефон и т. д. Так на каждую площадку у вас уйдет по пять-семь минут. Но этот процесс можно автоматизировать. Задаете в программе для парсинга условия выборки и через какое-то время получаете готовую таблицу со списком сайтов и телефонов.
Плюсы парсинга очевидны — если сравнивать его с ручным сбором и сортировкой данных:
- вы получаете данные очень быстро;
- можно задавать десятки параметров для составления выборки;
- в отчете не будет ошибок;
- парсинг можно настроить с определенной периодичностью — например, собирать данные каждый понедельник;
- многие парсеры не только собирают данные, но и советуют, как исправить ошибки на сайте.
Парсинг сайтов python. Часть 1
Анализ данных предполагает, в первую очередь, наличие этих данных. Первая часть доклада рассказывает о том, что делать, если у вас не имеется готового/стандартного датасета, либо он не соответствует тому, каким должен быть. Наиболее очевидный вариант - скачать данные из интернета. Это можно сделать множеством способов, начиная с сохранения html-страницы и заканчивая Event loop (моделью событийного цикла). Последний основан на параллелизме в JavaScript, что позволяет значительно повысить производительность. В парсинге event loop реализуется с помощью технологии AJAX, утилит вроде Scrapy или любого асинхронного фреймворка.
Извлечение данных из html связано с обходом дерева, который может осуществляться с применением различных техник и технологий. В докладе рассматриваются три «языка» обхода дерева: CSS-селекторы, XPath и DSL. Первые два состоят в довольно тесном родстве и выигрывают за счет своей универсальности и широкой сфере применения. DSL (предметно-ориентированный язык, domain-specific language) для парсинга существует довольно много, и хороши они, в первую очередь, тем, что удобство работы с ним осуществляется благодаря поддержке IDE и валидации со стороны языка программирования.
Для тренировки написания пауков компанией ScrapingHub создан учебный сайт toscrape.com , на примере которого рассматривается парсинг книжного сайта. С помощью chrome-расширения SelectorGadget , которое позволяет генерировать CSS-селекторы, выделяя элементы на странице, можно облегчить написание скрапера.
Пример с использованием scrapy :
import scrapy
class BookSpider(scrapy.Spider):
name = 'books'
start_urls =
def parse(self, response):
for href in response.css('.product_pod a::attr(href)').extract():
url = response.urljoin(href)
print(url)
Пример без scrapy:
import json
from urllib.parse import urljoin
import requests
from parsel import Selector
index = requests.get('http://books.toscrape.com/')
books =
for href in Selector(index.text).css('.product_pod a::attr(href)').extract():
url = urljoin(index.url, href)
book_page = requests.get(url)
sel = Selector(book_page.text)
books.append({
'title': sel.css('h1::text').extract_first(),
'price': sel.css('.product_main .price_color::text')extract_first(),
'image': sel.css('#product_gallery img::attr(src)').extract_first()
})
with open('books.json', 'w') as fp:
json.dump(books, fp)
Некоторые сайты сами помогают парсингу с помощью специальных тегов и атрибутов html. Легкость парсинга улучшает SEO сайта, так как при этом обеспечивается большая легкость поиска сайта в сети.