The Top 7 Python Libraries for Web Scraping in 2025
- The Top 7 Python Libraries for Web Scraping in 2025
- Связанные вопросы и ответы
- Какие библиотеки Python для веб-скрапинга будут наиболее популярными в 2025 году
- Какие новые библиотеки Python для веб-скрапинга могут появиться в 2025 году
- Какие из существующих библиотек Python для веб-скрапинга будут наиболее актуальными в 2025 году
- Какие библиотеки Python для веб-скрапинга могут быть наиболее эффективными для обработки больших объемов данных
- Какие библиотеки Python для веб-скрапинга могут быть наиболее удобными для использования
- Какие библиотеки Python для веб-скрапинга могут быть наиболее безопасными для использования
- Какие библиотеки Python для веб-скрапинга могут быть наиболее гибкими и настраиваемыми
The Top 7 Python Libraries for Web Scraping in 2025
Web scraping is the process of extracting data from websites. Python is a popular programming language for web scraping due to its simplicity and the availability of various libraries that make the process easier. In this article, we will discuss the top 7 Python libraries for web scraping in 2025.
H2. BeautifulSoup
BeautifulSoup is a popular Python library for web scraping. It is easy to use and provides a simple interface for parsing HTML and XML documents. With BeautifulSoup, you can easily extract data from web pages and navigate through the document tree.
H2. Scrapy
Scrapy is a powerful Python framework for web scraping. It provides a complete solution for web scraping, including downloading web pages, extracting data, and storing the data in a structured format. Scrapy is highly customizable and can be used for large-scale web scraping projects.
H2. Requests
Requests is a Python library for making HTTP requests. It is easy to use and provides a simple interface for sending HTTP requests and handling responses. Requests can be used for web scraping, but it is not specifically designed for this purpose.
H2. Selenium
Selenium is a powerful Python library for automating web browsers. It can be used for web scraping by automating the process of navigating through web pages and extracting data. Selenium is particularly useful for web scraping dynamic web pages that are generated using JavaScript.
H2. PyQuery
PyQuery is a Python library for working with HTML and XML documents. It provides a simple interface for selecting and manipulating elements in a document. PyQuery is similar to jQuery, a popular JavaScript library for working with HTML documents.
H2. LXML
LXML is a Python library for working with XML and HTML documents. It provides a simple interface for parsing and manipulating documents. LXML is highly efficient and can handle large documents quickly.
H2. MechanicalSoup
MechanicalSoup is a Python library for automating web browsers. It is similar to Selenium, but it is simpler and easier to use. MechanicalSoup can be used for web scraping by automating the process of navigating through web pages and extracting data.
H2. Conclusion
These are the top 7 Python libraries for web scraping in 2025. Each library has its own strengths and weaknesses, and the best library for a particular project will depend on the specific requirements of the project.
Связанные вопросы и ответы:
Вопрос 1: Что такое веб-скрейпинг и для чего он используется
Ответ: Веб-скрейпинг - это процесс автоматического извлечения данных с веб-сайтов. Он используется для сбора информации из интернета, которая может быть использована для различных целей, таких как анализ рынка, мониторинг конкурентов, поиск информации и т.д. Веб-скрейпинг позволяет автоматизировать процесс сбора информации, что может быть очень полезно для тех, кто работает с большими объемами данных.
Вопрос 2: Какие библиотеки Python можно использовать для веб-скрейпинга в 2025 году
Ответ: В 2025 году можно будет использовать следующие библиотеки Python для веб-скрейпинга: BeautifulSoup, Scrapy, Selenium, PyQuery, Requests-HTML, Lxml и PySpider.
Вопрос 3: Какая библиотека Python является наиболее популярной для веб-скрейпинга
Ответ: Наиболее популярной библиотекой Python для веб-скрейпинга является BeautifulSoup. Она используется многими разработчиками из-за своей простоты и удобства использования.
Вопрос 4: Какая библиотека Python может быть использована для управления браузером и взаимодействия с веб-сайтами
Ответ: Selenium - это библиотека Python, которая может быть использована для управления браузером и взаимодействия с веб-сайтами. Она позволяет автоматизировать процесс взаимодействия с веб-сайтами, что может быть очень полезно для тех, кто работает с динамическими веб-сайтами.
Вопрос 5: Какая библиотека Python может быть использована для парсинга XML и HTML
Ответ: Lxml - это библиотека Python, которая может быть использована для парсинга XML и HTML. Она основана на библиотеке libxml2 и предоставляет мощные инструменты для работы с XML и HTML.
Вопрос 6: Какая библиотека Python может быть использована для многопоточного веб-скрейпинга
Ответ: PySpider - это библиотека Python, которая может быть использована для многопоточного веб-скрейпинга. Она позволяет автоматизировать процесс сбора информации с веб-сайтов, используя многопоточность, что может быть очень полезно для тех, кто работает с большими объемами данных.
Какие библиотеки Python для веб-скрапинга будут наиболее популярными в 2025 году
В мире веб-скрапинга **BeautifulSoup** является одним из самых популярных инструментов для начинающих программистов на Python. Эта библиотека предоставляет удобные средства для извлечения данных из HTML и XML файлов. С её помощью можно легко находить необходимые теги, атрибуты и тексты, что делает её идеальным выбором для тех, кто только начинает своё погружение в мир сбора данных с веб-страниц.
- Поиск элементов: BeautifulSoup позволяет выполнять поиск по тегам, классам, идентификаторам и другим атрибутам, что делает процесс выборки данных гибким и точным.
- Навигация по дереву: С помощью методов
.parent,.children,.next_siblingи.previous_siblingможно легко перемещаться по DOM-дереву документа. - Изменение и модификация: Если вам нужно не только извлечь данные, но и изменить HTML-код, BeautifulSoup предоставляет функции для редактирования и удаления тегов.
- Кодировка: Автоматическое преобразование документа в удобную для работы кодировку UTF-8.
Кроме того, использование **BeautifulSoup** в сочетании с библиотекой **requests** для отправки HTTP-запросов делает процесс веб-скрапинга почти тривиальным. Ниже представлена таблица с примерами методов, которые часто используются при работе с BeautifulSoup:
| Метод | Описание |
|---|---|
find() | Поиск первого элемента с заданными параметрами |
find_all() | Поиск всех элементов, соответствующих заданным параметрам |
get_text() | Извлечение текста из элемента |
select() | Поиск элементов, соответствующих CSS-селектору |
Эти возможности делают **BeautifulSoup** отличным стартовым инструментом для тех, кто хочет освоить веб-скрапинг на Python, не вдаваясь в сложности более продвинутых библиотек.
Какие новые библиотеки Python для веб-скрапинга могут появиться в 2025 году
Python — высокоуровневый язык программирования общего назначения. Все больше людей котрибьютят в его экосистему:
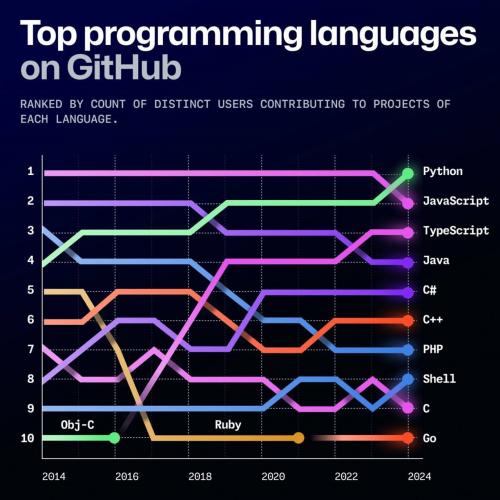
Думаю, популярность Python обусловлена его исторически сложившимся лидировнием в нескольких направлениях. Вот некоторые из них:
ML . Молодые ученые всего мира обмениваются jupyter notebook — это уже стало промышленным стандартом.
Data Scientist . Используют Python благодаря огромному количеству высокопроизводительных библиотек.
Разработка backend-сервисов . В Python есть уже несколько замечательных проектов фреймворков микросервисов — это и FastAPI, и Litestar, собравшие много тысяч звезд на GitHub, и фреймворк сервисов Django.
На мой взгляд, Python — самый перспективный ЯП. К тому же это язык высокого уровня, так что осваивать его одно удовольствие. Он продолжит завоевывать сердца молодых ученых и разработчиков, в том числе благодаря таким преимуществам:
Легкость чтения . В синтаксисе Python уже заложена простота и читабельность кода. Это делает язык подходящим для быстрой и эффективной разработки.
Впечатляющее количество модулей, библиотек и фреймворков . Многие из них разработаны крупными корпорациями, в которые инвестированы огромные финансовые и человеческие ресурсы.
Легкость входа и передачи .
Выше я перечислила преимущества Python для разработчиков, но на популярность ЯП еще влияет бизнес. Убеждена, что Python — лучший друг бизнеса, ведь он выгоден для большинства случаев. Один Python-разработчик пишет фичи с такой же скоростью, что и 3–4 Java-разработчика. Конечно, на Python пока не будешь раздавать
Python не собирается терять позиции в мире ИИ и машинного обучения . Библиотеки вродеTensorFlow, PyTorch и Scikit-learnпродолжают развиваться и обновляться и помогают разработчикам создавать более хитроумные модели. В ближайшие годы мы увидим, как Python будет использоваться еще шире в предсказательной аналитике, автоматизации с помощью ИИ и обработке естественного языка.
При этом Python по-прежнему остается незаменимым инструментом в анализе данных . БиблиотекиPandas и NumPyсовершенствуются и предлагают сложные возможности для анализа и обработки данных. В 2025 году Python будет применяться в анализе медицинских данных в здравоохранении, прогнозировании рыночных тенденций в финансах и не только.
Библиотеки, такие какQiskit, делают квантовое программирование доступным и открывают новые возможности в криптографии и вычислительной химии. Этот ЯП участвует и в развитии IoT :MicroPython и CircuitPythonпомогают программировать микроконтроллеры, разрабатываются эффективные и масштабируемые системы. Python применяется в умных домах, промышленной автоматизации и носимых устройствах.
Какие из существующих библиотек Python для веб-скрапинга будут наиболее актуальными в 2025 году
Визуализация данных (Data Visualization) играет важную роль в понимании данных, а также в том, чтобы рассказать с их помощью содержательную историю — жизненно важный навык в области Data Science. В Python существует множество библиотек, которые помогут вам создать красивые, интуитивно понятные визуальные эффекты. Мы выделим две из них благодаря стабильности и простоте использования: Matplotlib и Seaborn .
Matplotlib
Matplotlib — это лучшая библиотека визуализации данных в Python. Вы можете создавать гистограммы, диаграммы рассеяния и т. п. всего за несколько строк кода.
Одно из преимуществ Matplotlib заключается в том, что графики очень хорошо настраиваются, поэтому визуализации будут соответствовать всем вашим потребностям.
import matplotlib.pyplot as plt
# Sample data
years =
values =
# Create a line plot
plt.plot(years, values, marker='o', linestyle='-', color='b', label='Value Growth')
# Add a title and labels
plt.title('Yearly Value Growth')
plt.xlabel('Year')
plt.ylabel('Value')
# Add a legend
plt.legend()
# Display the plot
plt.show()
Пример использования библиотеки Matplotlib для создания простого линейного графика
Seaborn
Seaborn — это высокоуровневый, простой в использовании пакет визуализации на языке Python, основанный на Matplotlib. Это отличный выбор для начинающих программистов. С помощью этой библиотеки вы можете создавать визуализации, используя всего одну строку кода.
Кроме того, Seaborn лучше интегрирован для работы с фреймами данных pandas, а создаваемые графики более привлекательны визуально.
Какие библиотеки Python для веб-скрапинга могут быть наиболее эффективными для обработки больших объемов данных
Beautiful Soup - это библиотека для веб-парсинга на языке Python, позволяющая извлекать данные из HTML- и XML-файлов. Она анализирует HTML- и XML-документы и генерирует дерево разбора веб-страниц, что упрощает извлечение данных.
Установка Beautiful Soup: Установить Beautiful Soup 4 можно с помощью скрипта "pip install beautifulsoup4″.
Необходимые условия:
- Python.
- Pip: Это система управления пакетами на основе Python.
Поддерживаемые возможности Beautiful Soup:
- Beautiful Soup работает со встроенным в Python парсером HTML и другими сторонними парсерами Python, такими как HTML5lib и lxml.
- Beautiful Soup использует подбиблиотеки Unicode и Dammit для автоматического определения кодировки документа.
- BeautifulSoup предоставляет питонический интерфейс и идиомы для поиска, навигации и модификации дерева разбора.
- Beautiful Soup автоматически преобразует входящие сущности HTML и XML в символы Unicode.
Преимущества Beautiful Soup:
- Предоставляет парсеры Python, такие как пакет "lxml" для обработки xml-данных и специальные парсеры для HTML.
- Разбирает документы в формате HTML. Для разбора документа как XML необходимо установить пакет lxml.
- Сокращает время, затрачиваемое на извлечение данных и разбор результатов веб-парсинга.
- Парсер Lxml построен на базе библиотек Си libxml2 и libxslt, обеспечивающих быстрый и эффективный разбор и обработку XML и HTML.
- Парсер Lxml способен обрабатывать большие и сложные HTML-документы. Это хороший вариант, если вы собираетесь перебирать большие объемы веб-данных.
- Может работать с неполным HTML-кодом.
Задачи Beautiful Soup:
- BeautifulSoup html.parser и html5lib не подходят для задач, критичных ко времени. Если время отклика имеет решающее значение, lxml может ускорить процесс парсинга.

Какие библиотеки Python для веб-скрапинга могут быть наиболее удобными для использования
Откройте для себя список лучших библиотек для парсинга JavaScript с открытым исходным кодом, выбранных и оцененных на основе критериев, изложенных выше.
Полный набор инструментов можно найти в нашем репозитории для парсинга Python на GitHub .
1. Selenium
Selenium — это библиотека для парсинга Python, которая в основном используется для автоматизации браузеров. Она дает вам все необходимое для взаимодействия с веб-страницами так же, как это сделал бы пользователь. Это делает ее идеальным средством для парсинга динамического контента, требующего выполнения JavaScript.
Selenium поддерживает несколько браузеров, таких как Chrome, Firefox, Safari и Edge, из одного и того же API. Это открывает возможности для нажатия кнопок, наведения курсора на элементы, заполнения форм и многого другого. В библиотеке также есть такие опции, как просмотр в headless-браузере, настраиваемое ожидание и выполнение JavaScript на странице.
Узнайте больше в нашем руководстве по веб-парсингу в Selenium .
Цель : предоставить высокоуровневый API для автоматизации выполнения браузерами таких задач, как тестирование и парсинг веб-страниц посредством взаимодействия с браузером
⚙️ Особенности :
- Поддержка взаимодействия со многими браузерами, включая Chrome, Firefox, Safari и Edge
- Может запускать браузеры в headless-режиме
- Может нажимать, вводить и выполнять другие действия пользователя с веб-элементами
- Явное и неявное ожидание обработки динамического контента и сложных взаимодействий
- Может делать скриншоты веб-страниц или даже отдельных элементов
- Поддержка интеграции прокси
- Может выполнять код JavaScript в браузере для пользовательских веб-взаимодействий прямо на странице
- Мощный API для управления браузерами, обработки сеансов и многого другого
Категория : автоматизация браузера
⭐ Звезды на GitHub : прим. 31,2 тыс.
Загрузки за неделю : прим. 4,7 млн
️ Частота релизов : примерно раз в месяц
Плюсы :
- Самый популярный инструмент автоматизации браузера на Python
- Множество онлайн-уроков, ресурсов, инструкций,
- Один из самых крупных и активно используемых инструментов
Минусы :
- Менее многофункциональный API по сравнению с более современными инструментами, такими как Playwright
- Механизм явного и неявного ожидания может привести к сбоям в логике
- Медленнее по сравнению с аналогичными инструментами
2. Requests
Requests — это библиотека для выполнения HTTP-запросов, которое является важным этапом веб-парсинга. Благодаря интуитивно понятному и многофункциональному API она упрощает отправку HTTP-запросов и обработку ответов. В частности, она поддерживает все методы HTTP (GET, POSTи т. д.), чтобы вы могли получать контент с веб-страниц и API.
Requests также может управлять файлами cookie, настраивать заголовки, обрабатывать параметры URL-адресов, отслеживать сеансы и многое другое. Поскольку она не поддерживает HTML-парсинг, она обычно используется вместе с такими библиотеками, как Beautiful Soup.
Выполните указания полного руководства, чтобы освоить библиотеку Requests на Python .
Цель : предоставить интуитивно понятный API для отправки HTTP-запросов на Python
⚙️ Особенности :
- Поддержка всех способов HTTP
- Может повторно использовать установленные соединения для нескольких запросов для экономии ресурсов
- Поддерживает URL-адреса с символами, отличными от ASCII
- Поддерживает интеграцию прокси
- Может сохранять файлы cookie по нескольким запросам
- Поддержка парсинга ответов в формате JSON
- Обеспечивает безопасное соединение путем проверки сертификатов SSL
Категория : HTTP-клиент
⭐ Звезды на GitHub : прим. 52,3 тыс.
Какие библиотеки Python для веб-скрапинга могут быть наиболее безопасными для использования
Для реализации веб-скрапинга в Python весьма полезной и мощной является библиотека requests. Она позволяет отправлять HTTP-запросы на сервер и получать ответ в виде HTML-страницы. Такой подход позволяет извлекать нужную информацию со страницы и использовать ее в своих проектах.
Начнем с отправки HTTP-запроса. Нам понадобится URL-адрес страницы, с которой мы хотим получить данные. С помощью функцииget()из библиотеки requests мы можем отправить GET-запрос на сервер и получить ответ.
Пример:
import requests
url = https://www.example.com
response = requests.get(url)Получив ответ от сервера, мы можем его проанализировать и извлечь нужную нам информацию. Веб-скрапинг позволяет автоматически извлекать данные со страницы и используется для различных задач, таких как сбор данных, мониторинг, анализ и многое другое.
Для работы с HTML-страницей, полученной в результате запроса, нам понадобится библиотека BeautifulSoup. Она предоставляет простой и удобный интерфейс для парсинга и обработки HTML-кода.
Внимание: Для установки библиотек requests и BeautifulSoup воспользуйтесь командами:pip install requestsиpip install beautifulsoup4
Далее мы можем использовать функции и методы BeautifulSoup для поиска и извлечения нужных элементов из HTML-страницы. Например, мы можем найти все заголовки на странице, извлечь ссылки, получить текстовое содержимое и многое другое.
Важно отметить, что при работе с веб-скрапингом необходимо быть внимательным к политике использования данных на сайте, с которого проводится скрапинг. Некоторые сайты могут запрещать или ограничивать скрапинг своих данных. Поэтому всегда рекомендуется ознакомиться с правилами использования сайта и уважать их.
В заключение, веб-скрапинг с помощью библиотеки requests в Python открывает широкие возможности для получения и использования данных со страниц. Она предоставляет нам возможность отправлять HTTP-запросы, получать HTML-страницы и извлекать нужную информацию. Благодаря этой библиотеке мы можем автоматизировать процесс сбора данных, упростить анализ информации и использовать полученные данные в своих проектах.
Какие библиотеки Python для веб-скрапинга могут быть наиболее гибкими и настраиваемыми
Выберите IT-профессию за один день
Бесплатный профориентационный проект
Пройдите тест и определите ваше направление в IT. Выигрывайте призы, получайте подарки и личный план развития через бесплатные гайды и карьерную консультацию
Участвовать бесплатно
Выберите IT-профессию за один деньПарсинг (англ. parsing — разбор) — это процесс автоматического анализа веб-сайтов для сбора структурированной информации. Еще парсинг часто называют веб-скрапингом. Представьте, что вы ищете на новостном сайте статьи про Python и сохраняете каждую в заметки: копируете заголовок и ссылку. С помощью парсинга можно автоматизировать этот процесс. Все данные будет искать и сохранять скрипт , а вам останется только проверять файл с результатами.
Часто парсинг используют боты, которые потом предоставляют доступ к собранным структурированным данным. Это может быть список статей на сайте, вакансий на платформе по поиску работы или предложений на досках объявлений. Например, один из героев нашего блога написал бот, который нашел ему работу за месяц. Если у сайта нет полноценного открытого API , то парсер ищет данные с помощью GET-запросов к серверу, а это создает дополнительную нагрузку на сервер.
Это накладывает некоторые этические ограничения на скрипты для парсинга веб-сайтов:
- не стоит отправлять слишком много запросов к серверу, главная задача — собрать полезные данные, а не положить инфраструктуру сервиса;
- если есть публичное API, то лучше использовать его;
- на сайте могут быть личные данные пользователей, к ним надо относиться бережно и внимательно.
Надо быть готовым к тому, что некоторые владельцы веб-сайтов ограничивают парсинг и пытаются с ним бороться. В этих случаях приходится смириться с политикой сервиса или использовать более продвинутых ботов, которые имитируют поведение пользователя и получают доступ к странице через собственный экземпляр браузера. Этот способ сложнее, чем отправка запроса на сервер, но надежнее.