Top 10 Web Scraping Project Ideas. Introduction:
- Top 10 Web Scraping Project Ideas. Introduction:
- Web Scraping course. Course Description
- Web Scraping is. Introduction:
- Ml pet projects ideas. Как распознать змею и получить работу: история одного pet-проекта
- Web Scraping tools. Top 30 Free Web Scraping Software in 2023
- Best website scraper. How does Web Scraping Service Work?
Top 10 Web Scraping Project Ideas. Introduction:
Undoubtedly, web scraping has gained wide popularity and acceptance these days. Nevertheless, you can make a nice career and earn well as a full-time or freelance web scraper. The web contains all the information irrespective of the industry, making Web Scraping quite essential. This information provides actionable insights for businesses to modify one’s business strategies and beat their competitors. So, if you are interested in web scraping and looking forward to turning this interest into a money-making opportunity, you must acquire a good experience of it through web scraping projects.
You can attune your workflow if you know the right data for your decision-making exercises around real-world problems. Regardless of whether you choose a large-scale web scraping project or a small scale, it can add great value to your web scraping knowledge and skill set.
Leading search engines like Google depend on large-scale web scraping. Smaller web scraping tasks can be used to solve small-level problems as well. There are several amazing large-scale and small-scale web scraping projects to take on. Web scraping use cases and applications can range from market research for strategy business projects to scraping for training ML models.
With the fast-paced development of anti-bot solutions and measures taken by websites and anti-bot providers, the game of web scraping is also advancing. And here we are with 10 hand-picked web scraping project ideas for 2022 to help you polish your web scraper development skill.
Web Scraping course. Course Description
The ability to build tools capable of retrieving and parsing information stored across the internet has been and continues to be valuable in many veins of data science. In this course, you will learn to navigate and parse html code, and build tools to crawl websites automatically. Although our scraping will be conducted using the versatile Python library scrapy, many of the techniques you learn in this course can be applied to other popular Python libraries as well, including BeautifulSoup and Selenium. Upon the completion of this course, you will have a strong mental model of html structure, will be able to build tools to parse html code and access desired information, and create a simple scrapy spiders to crawl the web at scale.
1
Introduction to HTML
FreeLearn the structure of HTML. We begin by explaining why web scraping can be a valuable addition to your data science toolbox and then delving into some basics of HTML. We end the chapter by giving a brief introduction on XPath notation, which is used to navigate the elements within HTML code.
Web Scraping Overview
50 xpWeb-scraping is not nonsense!
50 xpHyperText Markup Language
50 xpHTML tree wordy navigation
50 xpFrom Tree to HTML
100 xpAttributes
50 xpKeep it Classy
100 xpFinding href
50 xpCrash Course in XPath
50 xpWhere am I?
100 xpIt's Time to P
100 xpA classy span
100 xp3
CSS Locators, Chaining, and Responses
Learn CSS Locator syntax and begin playing with the idea of chaining together CSS Locators with XPath. We also introduce Response objects, which behave like Selectors but give us extra tools to mobilize our scraping efforts across multiple websites.
From XPath to CSS
50 xpThe (X)Path to CSS Locators
100 xpGet an "a" in this Course
100 xpThe CSS Wildcard
100 xpCSS Attributes and Text Selection
50 xpYou've been `href`ed
100 xpTop Level Text
100 xpAll Level Text
100 xpRespond Please!
50 xpResponding with Selectors
100 xpSelecting from a Selection
100 xpSurvey
50 xpTitular
100 xpScraping with Children
100 xp4
Spiders
Learn to create web crawlers with scrapy. These scrapy spiders will crawl the web through multiple pages, following links to scrape each of those pages automatically according to the procedures we've learned in the previous chapters.
Web Scraping is. Introduction:
Web scraping is a process to crawl various websites and extract the required data using spiders. This data is processed in a data pipeline and stored in a structured format. Today, web scraping is widely used and has many use cases:
- Using web scraping, Marketing & Sales companies can fetch lead-related information.
- Web scraping is useful for Real Estate businesses to get the data of new projects, resale properties, etc.
- Price comparison portals, like Trivago, extensively use web scraping to get the information of product and price from various e-commerce sites.
The process of web scraping usually involves spiders , which fetch the HTML documents from relevant websites, extract the needed content based on the business logic, and finally store it in a specific format. This blog is a primer to build highly scalable scrappers. We will cover the following items:
- Ways to scrape : We’ll see basic ways to scrape data using techniques and frameworks in Python with some code snippets.
- Scraping at scale : Scraping a single page is straightforward, but there are challenges in scraping millions of websites, including managing the spider code, collecting data, and maintaining a data warehouse. We’ll explore such challenges and their solutions to make scraping easy and accurate.
- Scraping Guidelines : Scraping data from websites without the owner’s permission can be deemed as malicious. Certain guidelines need to be followed to ensure our scrappers are not blacklisted. We’ll look at some of the best practices one should follow for crawling.
So let’s start scraping.
Ml pet projects ideas. Как распознать змею и получить работу: история одного pet-проекта
Специалист по компьютерному зрению рассказывает, как увлечение рептилиями помогло перейти из юриспруденции в Data Science.
Один из способов впечатлить работодателей, которые ждут от вас опыта, — это яркий pet-проект. В нем можно реализовать свои навыки и идеи, изучить актуальные технологии на практике. О том, как pet-проект помог при трудоустройстве, рассказал Аргишти Саакян, Computer Vision Researcher в компании Diagnocat.
Освойте профессию «Data Scientist»
Подробнее
Часть 1: Я решал типовые задачи с Kaggle и не получил выхлопа
Я пришел в IT из юридической сферы, окончил МГЮА (Московская государственная юридическая академия). Знания о больших данных и компьютерном зрении собирал по кусочкам: отдельно прошел курс по Python, отдельно — по статистике. Параллельно смотрел много материалов на,,.
Чтобы пробиться в Data Science без технического высшего образования, я просто обязан был показать pet-проекты.Нужно было, чтобы на меня обратили внимание. Вначале я решал классические задачи из— соцсети для дата-сайентистов. Проекты были типовые — например, построить модель для предсказания цен на жилье. Выхлоп для собеседований с таких проектов был слабым. У меня никогда не спрашивали: «Почему ты выбрал эту задачу, как ты ее решал?»
Так без результата прошли 5–7 собеседований. В итоге я устроился работать просто аналитиком данных, без нейросетей, и решил серьезно заняться pet-проектом.
Часть 2: Я создал классификацию змей
Мне хотелось поработать с алгоритмами компьютерного зрения. Базовый тип задач в этой области — классификация. Оставался вопрос: что классифицировать? Мне интересны змеи и рептилии, поэтому я решил создать классификацию змей, которые обитают в Московской области.
Больше всего времени ушло на сбор данных. Я искал фотографии нужных мне видов змей в Google, Яндексе. Самой сложной задачей оказалось создать пайплайн для обучения нейросети. Я писал алгоритм на, использовал библиотеки,, PIL. В основу сервиса я положил алгоритм сверточных нейронных сетей, архитектуру EfficientNet.
Так выглядит процесс обучения нейросети в коде. Источник: Github
Все данные я поделил на три части, одну из них использовал только для тестирования. Я считал метрики при помощи confusion matrix, а также лично смотрел, как нейросеть справляется в разных кейсах. Точность выше 94% я не получил, но на тот момент это был неплохой результат.
Такие результаты модель показала на тестовых данных. Источник: GitHub
Затем я написал Telegram-бот, в который можно загрузить фото змеи, а нейросеть ее распознает.
Задача была интересной и полезной для меня, я столкнулся с рядом реальных проблем и научился их решать. На создание проекта с нуля ушло около трех недель, я работал в свободное время, с перерывами. Мне было интересно, поэтому я часто залипал в работу надолго.
Часть 3 (happy end): Я получил работу мечты с машинным зрением
Через полгода работы аналитиком я снова начал искать вакансии. К тому моменту я уже опубликовал свой проект наи дал в нем ссылку на телеграм-бот. На собеседованиях у меня всегда спрашивали про этот проект: почему я выбрал именно классификацию змей, с какими трудностями столкнулся. В проекте я использовал разные технологии, поэтому он получился намного показательнее сухой задачи с Kaggle. Для одной из вакансий это был релевантный опыт — так я попал в компанию, где начал заниматься машинным зрением.
Советы новичкам, которые хотят завести pet-проект
Выбирайте то, что вам интересно. Это поможет сделать живой проект, который привлечет к вам внимание работодателей.
Берите реальную проблему. Чтобы не застрять на середине пути, нужно всегда иметь перед глазами понятную цель, зачем вы этот проект делаете.
Постройте план и таймлайн работы. Проект важно не только начать, но и закончить. Чтобы не увязнуть в нем на слишком долгий срок, поставьте себе четкие временные рамки.
Используйте актуальные технологии. Это покажет, что вы следите за развитием своей сферы и готовы учиться новым инструментам на практике.
Работайте честно. Да, pet-проект — это не рабочий проект, но относиться к нему нужно со всей серьезностью. Это поможет вам максимально реализовать свои навыки в работе и научиться чему-то в процессе. Если в конце кажется, что сервис не работает так, как должен, если нужно было делать всё иначе, переделайте. Только так pet-проект даст вам развитие.
Pet-проект — это возможность реализовать свою идею, поработать «для души» и одновременно показать, на что вы способны. Это отличная практика навыков для начинающих, способ получить опыт, который поможет трудоустроиться.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.
Web Scraping tools. Top 30 Free Web Scraping Software in 2023
Web Scraping & Web Scraping Software
Web scraping (also termed web data extraction, screen scraping, or web harvesting) is a technique of extracting data from websites. It turns web data scattered across pages into structured data that can be stored in your local computer in a spreadsheet or transmitted to a database.
It can be difficult to build a web scraper for people who don’t know anything about coding. Luckily, there is data scraping software available for people with or without programming skills. Also, if you're a data scientist or a researcher, using a web scraper definitely raises your working effectiveness in data collection.
Here is a list of the 30 most popular free web scraping software . I just put them together under the umbrella of software, while they range from open-source libraries, browser extensions to desktop software and more.
Best 30 Free Web Scraping Tools
Who is this for: developers who are proficient at programming to build a web scraper/web crawler to crawl the websites.
Why you should use it: Beautiful Soup is an open-source Python library designed for web-scraping HTML and XML files. It is the top Python parser that has been widely used. If you have programming skills, it works best when you combine this library with Python.
Who is this for: Professionals without coding skills who need to scrape web data at scale. This web scraping software is widely used among online sellers, marketers, researchers and data analysts.
Why you should use it: Octoparse is a free for life SaaS web data platform. With its intuitive interface, you can scrape web data within points and clicks. It also provides ready-to-use web scraping templates to extract data from Amazon, eBay, Twitter, BestBuy, etc. If you are looking for a one-stop data solution, Octoparse also provides web data service . Or you can simply follow the Octoparse user guide to scrape website data easily for free.
Who is this for: Enterprises with budget looking for integration solutions on web data.
Why you should use it: Import.io is a SaaS web data platform. It provides a web scraping solution that allows you to scrape data from websites and organize them into data sets. They can integrate the web data into analytic tools for sales and marketing to gain insight.
Who is this for: Enterprises and businesses with scalable data needs.
Why you should use it: Mozenda provides a data extraction tool that makes it easy to capture content from the web. They also provide data visualization services. It eliminates the need to hire a data analyst. And Mozenda team offers services to customize integration options.
Who is this for: Data analysts, marketers, and researchers who lack programming skills.
Why you should use it: ParseHub is a visual web scraping tool to get data from the web. You can extract the data by clicking any fields on the website. It also has an IP rotation function that helps change your IP address when you encounter aggressive websites with anti-scraping techniques.
Who is this for: SEO and marketers
Why you should use it: CrawlMonster is a free web scraping tool. It enables you to scan websites and analyze your website content, source code, page status, etc.
Who is this for: Enterprise looking for integration solution on web data.
Why you should use it: Connotate has been working together with Import.io, which provides a solution for automating web data scraping. It provides web data service that helps you to scrape, collect and handle the data.
Who is this for: Researchers, students, and professors.
Why you should use it: Common Crawl is founded by the idea of open source in the digital age. It provides open datasets of crawled websites. It contains raw web page data, extracted metadata, and text extractions.
9. Crawly
Who is this for: People with basic data requirements.
Why you should use it: Crawly provides automatic web scraping service that scrapes a website and turns unstructured data into structured formats like JSON and CSV. They can extract limited elements within seconds, which include Title Text, HTML, Comments, DateEntity Tags, Author, Image URLs, Videos, Publisher and country.
Best website scraper. How does Web Scraping Service Work?
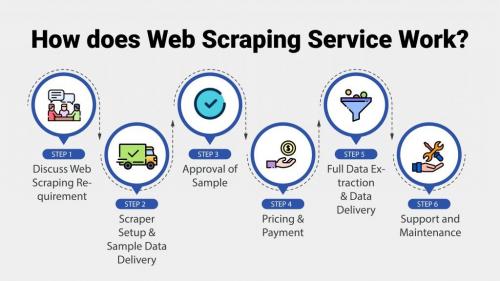
Before we go into the web scraping services, let’s understand the process of how a service works:
1. Discuss Web Scraping Requirement : It starts with an initial interaction and discussion regarding what your requirements are. This will help the service understand what you are looking for and serve you accordingly.
2. Scraper Setup & Sample Data Delivery : Based on your requirements, the service would build a sample scraper to extract the data you want. Once some of that data is scraped, the service would share the sample data with you for review. This will give you a sense of the quality and quantity of data you are likely to get.
3. Approval of Sample : Once you have seen and reviewed the data, you can give your feedback and suggestions, if any. Else, you can approve the sample and the service can move forward with extraction of the rest of the data you need.
4. Pricing & Payment : Once you approve the sample data and give a go-ahead for the full extraction of the data, it all comes down to pricing and payment. You need to work out the pricing and payment modalities with the service. This sort of seals the contract.
5. Full Data Extraction & Data Delivery : Now the service would rigorously work on the extraction of the data you need. Once the extraction is over, the service would deliver the data in the way discussed and agreed upon by the two parties.
6. Support and Maintenance : This is the part that takes care of the quality. The service would strive to provide clean and actionable data to you. At the same time, if there are any issues later, the service would also provide immediate and prompt customer support as well.