Top 10 Web Scraping Tools in 2023 to Extract Webpage Data. 2023 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
- Top 10 Web Scraping Tools in 2023 to Extract Webpage Data. 2023 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
- Scrapy. Introducing Scrapy
- Web Scraper python. Scrape and Parse Text From Websites
- Web Scraper инструкция. Парсинг без кода. Тестовый урок
- Web Scraping open source. Scrapy
- Scraping Bot. What Is a Scraper Bot
- How to get Data From website. 16 Tools to extract Data From website
Top 10 Web Scraping Tools in 2023 to Extract Webpage Data. 2023 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
322 views
Abstract: This article will introduce the top10 best web scraping tools in 2023. ScrapeStorm Free Download
Web scraping tools are designed to grab the information needed on the website. Such tools can save a lot of time for data extraction.
Here is a list of 10 recommended tools with better functionality and effectiveness.
1. ScrapeStorm
ScrapeStorm is an AI-Powered visual web scraping tool,which can be used to extract data from almost any websites without writing any code.
It is powerful and very easy to use. You only need to enter the URLs, it can intelligently identify the content and next page button, no complicated configuration, one-click scraping.
ScrapeStorm is a desktop app available for Windows, Mac, and Linux users. You can download the results in various formats including Excel, HTML, Txt and CSV. Moreover, you can export data to databases and websites.
Features:
1) Intelligent identification
2) IP Rotation and Verification Code Identification
3) Data Processing and Deduplication
4) File Download
5) Scheduled task
6) Automatic Export
8) Automatic Identification of E-commerce SKU and big images
Pros:
1) Easy to use
2) Fair price
3) Visual point and click operation
4) All systems supported
Cons:
No cloud services
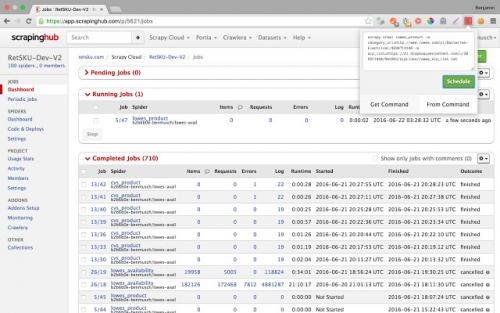
2.ScrapingHub
Scrapinghub is the developer-focused web scraping platform to offer several useful services to extract structured information from the Internet.
Scrapinghub has four major tools – Scrapy Cloud, Portia, Crawlera, and Splash.
Features:
1) Allows you to converts the entire web page into organized content
2) JS on-page support toggle
3) Handling Captchas
Pros:
1) Offer a collection of IP addresses covered more than 50 countries which is a solution for IP ban problems
2) The temporal charts were very useful
3) Handling login forms
4) The free plan retains extracted data in cloud for 7 days
Cons:
1) No Refunds
2) Not easy to use and needs to add many extensive add-ons
3) Can not process heavy sets of data
3.Dexi.io
Web Scraping & intelligent automation tool for professionals. Dexi.io is the most developed web scraping tool which enables businesses to extract and transform data from any web source through with leading automation and intelligent mining technology.
Dexi.io allows you to scrape or interact with data from any website with human precision. Advanced feature and APIs helps you transform and combine data into powerfull datasets or solutions.
Features:
1) Provide several integrations out of the box
2) Automatically de-duplicate data before sending it to your own systems.
3) Provide the tools when robots fail
Pros:
1) No coding required
2) Agents creation services available
Cons:
1) Difficult for non-developers
2) Trouble in Robot Debugging
4.Diffbot
https://www.youtube.com/embed/qH9VYKxU1NI
Diffbot allows you to get various type of useful data from the web without the hassle. You don’t need to pay the expense of costly web scraping or doing manual research. The tool will enable you to exact structured data from any URL with AI extractors.
Scrapy. Introducing Scrapy
A framework is a reusable, “semi-complete” application that can be specialized to produce custom applications. (Source: Johnson & Foote, 1988 )
In other words, the Scrapy framework provides a set of Python scripts that contain most of the code required to use Python for web scraping. We need only to add the last bit of code required to tell Python what pages to visit, what information to extract from those pages, and what to do with it. Scrapy also comes with a set of scripts to setup a new project and to control the scrapers that we will create.
It also means that Scrapy doesn’t work on its own. It requires a working Python installation (Python 2.7 and higher or 3.4 and higher - it should work in both Python 2 and 3), and a series of libraries to work. If you haven’t installed Python or Scrapy on your machine, you can refer to the setup instructions . If you install Scrapy as suggested there, it should take care to install all required libraries as well.
scrapy version
in a shell. If all is good, you should get the following back (as of February 2017):
Scrapy 2.1.0
If you have a newer version, you should be fine as well.
To introduce the use of Scrapy, we will reuse the same example we used in the previous section. We will start by scraping a list of URLs from the list of faculty of the Psychological & Brain Sciences and then visit those URLs to scrape detailed information about those faculty members.
Web Scraper python. Scrape and Parse Text From Websites
Collecting data from websites using an automated process is known as web scraping. Some websites explicitly forbid users from scraping their data with automated tools like the ones that you’ll create in this tutorial. Websites do this for two possible reasons:
- The site has a good reason to protect its data. For instance, Google Maps doesn’t let you request too many results too quickly.
- Making many repeated requests to a website’s server may use up bandwidth, slowing down the website for other users and potentially overloading the server such that the website stops responding entirely.
Before using your Python skills for web scraping, you should always check your target website’s acceptable use policy to see if accessing the website with automated tools is a violation of its terms of use. Legally, web scraping against the wishes of a website is very much a gray area.
Important: Please be aware that the following techniqueswhen used on websites that prohibit web scraping.
For this tutorial, you’ll use a page that’s hosted on Real Python’s server. The page that you’ll access has been set up for use with this tutorial.
Now that you’ve read the disclaimer, you can get to the fun stuff. In the next section, you’ll start grabbing all the HTML code from a single web page.
Build Your First Web Scraper
One useful package for web scraping that you can find in Python’s standard library isurllib, which contains tools for working with URLs. In particular, the urllib.request module contains a function calledurlopen()that you can use to open a URL within a program.
In IDLE’s interactive window, type the following to importurlopen():
The web page that you’ll open is at the following URL:
To open the web page, passurltourlopen():
urlopen()returns anHTTPResponseobject:
To extract the HTML from the page, first use theHTTPResponseobject’s.read()method, which returns a sequence of bytes. Then use.decode()to decode the bytes to a string using:
Now you can print the HTML to see the contents of the web page:
The output that you’re seeing is the HTML code of the website, which your browser renders when you visithttp://olympus.realpython.org/profiles/aphrodite:
Withurllib, you accessed the website similarly to how you would in your browser. However, instead of rendering the content visually, you grabbed the source code as text. Now that you have the HTML as text, you can extract information from it in a couple of different ways.
Web Scraper инструкция. Парсинг без кода. Тестовый урок
Парсим без кода с помощью парсера WebScraper.
Скачать и установить расширение http://webscraper.io
Текст в
Парсер Web Scraper — это расширение для браузера.
Перейдём к примеру парсинга. Задача — собрать цены на товары. Сайт — Леруа Мерлен.
Категория — товары для дачи. Открываем парсер в панели разработчика. Нажимаем F12 и переходим во вкладку WebScraper.
Создаём новую карту сайта – сайтмап. Cайтмап – это инструкция парсеру, какие данные собирать.
Start URL – ссылка, с которой начинается парсинг.
Данные, которые нас интересуют, находятся в карточках товаров.
Для этого укажем парсеру, какие элементы на странице нужно собрать.
Чтобы что-то выбрать, используем selector. Selector – это такой отборщик, который со всей страницы выбирает только указанные элементы.
Селектором может быть что угодно: ссылка, текст, целый блок.
В параметрах селектора выбираем его тип, чтобы указать парсеру, что мы
ищем.
Чтобы вытащить название и цену, нам нужно указать блок с карточкой товара.
Выбираем тип – Element и мышкой наводим на нужный блок.
Блок подсвечивается красным.
Чтобы собрать все подобные элементы — отмечаем чекбокс Multiple. Если этот чекбокс оставить пустым — будет собрано только первое значение.
Выбираем элемент, проваливаемся в него и указываем следующие селекторы.
Тип text – название товара.
Тип text – цена.
Посмотрите на Selector Graph – карту парсера.
Это схема наших селекторов.
Нажимаем Scrap, чтобы запустить парсер.
Парсер перейдёт по указанной ссылке, подождёт пока страница загрузится и соберёт данные.
Обратите внимание на эти два параметра.
Request interval — интервал между запросами, то есть через сколько секунд переходить по новой ссылке.
Page load delay — ожидание загрузки, то есть сколько секунд подождать, пока страница
загрузится.
Оставляем настройки по умолчанию – 2 секунды.
Если сделать меньше, парсер могут заблокировать.
Запустим парсер.
Парсер откроет страницу, соберёт с неё данные и сохранит в своей базе.
Мы можем предварительно посмотреть результат:
Browse – Refresh Data (Просмотр – обновить данные).
Отлично, мы собрали данные о ценах, но только с первой страницы.
Чтобы собрать данные с остальных страниц, будем работать с пагинацией.
Самый простой способ работы с пагинацией, когда известно количество страниц.
Как видите в адресе страницы меняется только последняя цифра, означающая её номер. Дадим указание парсеру — допишем диапазон страниц в квадратных скобках.
Парсер автоматически подставит нужное значение в адрес ссылки и пройдёт по всем
страницам.
Источник: https://lajfhak.ru-land.com/stati/top-13-web-scraping-tools-2023-so-what-does-web-scraper-do
Web Scraping open source. Scrapy
Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format. One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large web scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use Scrapy.
Scrapy has a couple of handy built-in export formats such as JSON, XML, and CSV. Its built for extracting specific information from websites and allows you to focus on the data extraction using CSS selectors and choosing XPath expressions. Scraping web pages using Scrapy is much faster than other open source tools so its ideal for extensive large-scale scaping. It can also be used for a wide range of purposes, from data mining to monitoring and automated testing. What stands out about Scrapy is its ease of use and . If you are familiar with Python you’ll be up and running in just a couple of minutes. It runs on Linux, Mac OS, and Windows systems.Scrapy is under BSD license.
Scraping Bot. What Is a Scraper Bot
Scraper bots are tools or pieces of code used to extract data from web pages. These bots are like tiny spiders that run through different web pages in a website to extract the specific data they were created to get.
The process of extracting data with a scraper bot is called web scraping . At the final stage of web scraping, the scraper bot exports the extracted data in the desired format (e.g JSON, Excel, XML, HTML, etc.) of the user.
As simple as this process might sound, there are a few web scraping challenges , and you can face that could hinder you from getting the data you want.
The practical uses of scraping bots
Scraper bots help people retrieve small-scale data from multiple websites. With these data, online directories like Job boards, Sports websites, and Real estate websites can be built. Aside from these, so much more can still be done with a scraper bot. Some of the popular practical uses we see include:
Market Research: Many online retailers rely on web scraping bots to help them understand their competitors and overall market dynamics. That way, they can develop strategies that will help them stay ahead of the competition.
Stock Market Analysis: For stock traders to predict the market, they need data and many of them get that data with web scraping. Stock price prediction and stock market sentiment analysis with web scraping is becoming a trending topic. If you are a stock trader, this is something you have to know about.
Search Engine Optimization (SEO): SEO companies rely heavily on web scraping for many things. First, in order to monitor the competitive position of their customers or their indexing status, web scraping is needed. Also, to find the right keywords for content, a scraper bot is used. With web scraping, there are so many actionable SEO hacks that can be implemented to optimize a web page.
How to get Data From website. 16 Tools to extract Data From website
In today's business world, smart data-driven decisions are the number one priority. For this reason, companies track, monitor, and record information 24/7. The good news is there is plenty of public data on servers that can help businesses stay competitive.
The process of extracting data from web pages manually can be tiring, time-consuming, error-prone, and sometimes even impossible. That is why most web data analysis efforts use automated tools.
Web scraping is an automated method of collecting data from web pages. Data is extracted from web pages using software called web scrapers, which are basically web bots.
What is data extraction, and how does it work?
Data extraction or web scraping pursues a task to extract information from a source, process, and filter it to be later used for strategy building and decision-making. It may be part of digital marketing efforts, data science, and data analytics. The extracted data goes through the ETL process (extract, transform, load) and is then used for business intelligence (BI). This field is complicated, multi-layered, and informative. Everything starts with web scraping and the tactics on how it is extracted effectively.
Before automation tools, data extraction was performed at the code level, but it was not practical for day-to-day data scraping. Today, there are no-code or low-code robust data extraction tools that make the whole process significantly easier.
What are the use cases for data extraction?
To help data extraction meet business objectives, the extracted data needs to be used for a given purpose. The common use cases for web scraping may include but are not limited to:
- Online price monitoring: to dynamically change pricing and stay competitive.
- Real estate: data for building real-estate listings.
- News aggregation: as an alternative data for finance/hedge funds.
- Social media: scraping to get insights and metrics for social media strategy.
- Review aggregation: scraping gathers reviews from predefined brand and reputation management sources.
- Lead generation: the list of target websites is scraped to collect contact information.
- Search engine results: to support SEO strategy and monitor SERP.
Is it legal to extract data from websites?
Web scraping has become the primary method for typical data collection, but is it legal to use the data? There is no definite answer and strict regulation, but data extraction may be considered illegal if you use non-public information. Every tip described below targets publicly available data which is legal to extract. However, it is still illegal is to use the scrapped data for commercial purposes.
How to extract data from a website
Manually extracting data from a website (copy/pasting information to a spreadsheet) is time-consuming and difficult when dealing with big data. If the company has in-house developers, it is possible to build a web scraping pipeline. There are several ways of manual web scraping.
1. Code a web scraper with Python
It is possible to quickly build software with any general-purpose programming language like Java, JavaScript, PHP, C, C#, and so on. Nevertheless, Python is the top choice because of its simplicity and availability of libraries for developing a web scraper.
2. Use a data service
Data service is a professional web service providing research and data extraction according to business requirements. Similar services may be a good option if there is a budget for data extraction.
3. Use Excel for data extraction
This method may surprise you, but Microsoft Excel software can be a useful tool for data manipulation. With web scraping, you can easily get information saved in an excel sheet. The only problem is that this method can be used for extracting tables only.
4. Web scraping tools
Modern data extraction tools are the top robust no-code/low code solutions to support business processes. With three types of data extraction tools – batch processing, open-source, and cloud-based tools – you can create a cycle of web scraping and data analysis. So, let's review the best tools available on the market.
How to Get Data From a Website: 16 Tools to Extract Data From a Website
In today's business world, smart data-driven decisions are the number one priority. For this reason, companies track, monitor, and record information 24/7. The good news is that there is plenty of public data on servers that can help businesses stay competitive.
The process of extracting data from web pages manually can be tiring, time-consuming, error-prone, and sometimes even impossible. That is why most web data analysis efforts use automated tools.
Web scraping is an automated method of collecting data from web pages. Data is extracted from web pages using software called web scrapers, which are basically web bots.
Data extraction or web scraping pursues a task to extract information from a source, process, and filter it to be later used for strategy building and decision-making. It may be part of digital marketing efforts, data science, and data analytics. The extracted data goes through the ETL process (extract, transform, load) and is then used for business intelligence (BI). This field is complicated, multi-layered, and informative. Everything starts with web scraping and the tactics on how it is extracted effectively.
Before automation tools, data extraction was performed at the code level, but it was not practical for day-to-day data scraping. Today, there are no-code or low-code robust data extraction tools that make the whole process significantly easier.
To help data extraction meet business objectives, the extracted data needs to be used for a given purpose. The common use cases for web scraping may include but are not limited to:
16 Tools to Extract Data From a Website
- Scrapy
- Apify
- RoboCopy
- Ahrefs
- Screaming Frog
- Moz
- Ahrefs
- Screaming Frog
- Moz
- Scrapy
- Apify
- Ahrefs
- Screaming Frog
- Moz
- Ahrefs
- Screaming Frog
- Moz
These 16 tools can help you extract data from a website and make informed business decisions. Remember to always check the terms of service for each website to ensure you are allowed to extract data.