Парсинг, что это такое простыми словами. Парсинг и краулинг: отличия
Парсинг, что это такое простыми словами. Парсинг и краулинг: отличия
Парсинг иногда путают с краулингом. Это происходит потому, что данные процессы схожи. Оба имеют идентичные варианты использования. Разница — в целях.
Обе операции «заточены» на обработку данных с сайтов. Процессы автоматизированы, поскольку используют роботов-парсеров. Что это такое? Всего лишь боты для обработки информации или контента.
И парсинг, и краулинг проводят анализ веб-страниц и поиск данных с помощью программных средств. Они никак не изменяют информацию, представленную там, и работают с ней напрямую.
Парсинг собирает данные и сортирует их для выдачи по заданным критериям. И это необязательно происходит в Интернете, где делают парсинг веб-страниц. Речь идет о данных, а не о том, где они хранятся.
Например, вы хотите поработать над ценовой аналитикой. Для этого вы запускаете созданные парсеры товаров и цен на них, чтобы собрать информацию с Avito или с любого интернет-магазина. Таким же образом можно анализировать данные фондового рынка, объявления по недвижимости и так далее.
Краулинг или веб-сканирование — прерогатива поисковых ботов или пауков. Краулинг включает в себя просмотр страницы целиком в поисках информации и ее индексацию, включая последнюю букву и точку. Но никакие данные при этом не извлекаются. Интернет-бот, он же — парсер поисковой системы — тоже систематически просматривает всемирную паутину для того, чтобы найти сайты и описать их содержимое. Самое важное отличие от краулера — он собирает данные и систематизирует их.
То, что делают Google, Яндекс или Yahoo — простой пример веб-сканирования. Это тоже своего рода парсинг. Что это такое простыми словами? Когда поисковые машины сканируют сайты и используют полученную информацию для индексации. Подробно об этом процессе можно прочитать в нашем глоссарии .
Парсинг это. Для чего парсинг нужен?
В первую очередь, целью парсинга является ценовая «разведка», ассортиментный анализ, отслеживание товарных акций. “Кто, что, за сколько и в каких количествах продаёт?” – основные вопросы, на которые парсинг должен ответить. Если говорить более подробно, то парсинг ассортимента конкурентов или того же Яндекс.Маркет отвечает на первые три вопроса.С оборотом товара несколько сложней. Однако, такие компании как “Wildberries”, “Lamoda“ и Леруа Мерлен, открыто предоставляют информацию об ежедневных объемах продаж (заказах) или остатках товара, на основе которой не сложно составить общее представлении о продажах (часто слышу мнение, мол эти данные могут искажаться намеренно — возможно, а возможно и нет). Смотрим, сколько было товара на складе сегодня, завтра, послезавтра и так в течении месяца и вот уже готов график и динамика изменения количества по позиции составлена (оборачиваемость товара фактически). Чем выше динамика, тем больше оборот. Потенциально возможный способ узнать оборачиваемость товаров с помощью ежедневного анализа остатков сайта Леруа Мерлен. Можно, конечно, сослаться на перемещение товаров между точками. Но суммарно, если брать, например, Москву — то число не сильно изменится, а в существенные передвижения товара по регионам верится с трудом.С объемами продаж ситуация аналогична. Есть, конечно, компании, которые публикуют информацию в виде много/мало, но даже с этим можно работать, и самые продаваемые позиции легко отслеживаются. Особенно, если отсечь дешёвые позиции и сфокусироваться исключительно на тех, что представляют наибольшую ценность. По крайней мере, мы такой анализ делали – интересно получалось.Во-вторых, парсинг используется для получения контента. Здесь уже могут иметь место истории в стиле “правовых оттенков серого”. Многие зацикливаются на том, что парсинг – это именно воровство контента, хотя это совершенно не так. Парсинг – это всего лишь автоматизированный сбор информации, не более того. Например, парсинг фотографий, особенно с “водяными знаками” – это чистой воды воровство контента и нарушение авторских прав. Потому таким обычно не занимаются (мы в своей работе ограничиваемся сбором ссылок на изображения, не более того… ну иногда просят посчитать количество фотографий, отследить наличие видео на товар и дать ссылку и т.п.).Касательно сбора контента, интересней ситуация с описаниями товаров. Недавно нам поступил заказ на сбор данных по 50 сайтам крупных онлайн-аптек. Помимо информации об ассортименте и цене, нас попросили “спарсить” описание лекарственных аппаратов – то самое, что вложено в каждую пачку и является т.н. фактической информацией, т.е. маловероятно попадает под закон о защите авторских прав. В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов. Но да, могут быть и авторские описания лекарств, которые заверены у нотариуса и сделаны специально как своего рода ловушки для воришек контента :).Рассмотрим также сбор описания книг, например, с ОЗОН.РУ или Лабиринт.ру. Здесь уже ситуация не так однозначна с правовой точки зрения. С одной стороны, использование такого описания может нарушать авторское право, особенно если описание каждой карточки с товаром было нотариально заверено (в чём я сильно сомневаюсь — ведь может и не быть заверено, исключение — небольшие ресурсы, которые хотят затаскать по судам воров контента). В любом случае, в данной ситуации придётся сильно «попотеть», чтобы доказать уникальность этого описания. Некоторые клиенты идут еще дальше — подключают синонимайзеры, которые «на лету» меняют (хорошо или плохо) слова в описании, сохраняя общий смысл.Ещё одно из применений парсинга довольно оригинально – “самопарсинг”. Здесь преследуется несколько целей. Для начала – это отслеживание того, что происходит с наполнением сайта: где битые ссылки, где описания не хватает, дублирование товаров, отсутствие иллюстраций и т.д. Полчаса работы парсера — и вот у тебя готовая таблица со всеми категориями и данными. Удобно! “Самопарсинг” можно использовать и для того, чтобы сравнить остатки на сайте со своими складскими остатками (есть и такие заказчики, отслеживают сбои выгрузок на сайт). Ещё одно применение “самопарсинга”, с которым мы столкнулись в работе — это структурирование данных с сайта для выгрузки их на Яндекс Маркет. Ребятам так проще было сделать, чем вручную этим заниматься.Также парсятся объявления, например, на ЦИАН-е, Авито и т.д. Цели тут могут быть как перепродажи баз риелторам или туроператорам, так и откровенный телефонный спам, ретаргетинг и т.п. В случае с Авито это особенно явно, т.к. сразу составляется таблица с телефонами пользователей (несмотря на то, что Авито подменяет телефоны пользователей для защиты и публикует их в виде изображения, от поступающих звонков все равно никуда не уйти).
Парсинг в ВК. 10 программ для парсинга ВК
Сервисов для парсинга сейчас великое множество. Однако мы предлагаем вам ознакомиться с десятью, которые тщательно проверены, ТОЧНО работают и не имеют серьезных нареканий со стороны пользователя.
Церебро Таргет
Найти программу можно на сайте церебро.рф . Действительно хороша. К вашим услугам более сотни параметров поиска и анализа целевой аудитории. Анализирует заданное сообщество, подбирает похожую аудиторию, даже из фотоальбомов конкурирующих сообществ умудряется информацию «надергать» (там ведь и снимки добавляют, и комментарии оставляют).
Проблема в том, что программа платная, при том денег нужно отдать сразу за месяц — 1225 рублей. Ни о каком тестовом периоде речь тоже не идет. И, пожалуй, она больше подойдет уже для опытного пользователя. Начинающему ТАКОЕ количество параметров просто не нужно.

TargetHunter
Размещается на официальном сайте targethunter.net . Тоже платный парсинг, но с куда более лояльной системой оплаты. Минимальная ставка — 100 рублей, срок действия — 2 дня. Так что можно попробовать программу, потеряв незначительную сумму, а дальше уже решать, нужна ли она вам и как часто.
Водится здесь и небольшой тестовый вариант. Включает в себя демонстрацию 24 инструментов и 1 поток задач. Хотите увидеть «полную силу» программы — покупайте.
С помощью TargetHunter можно собрать информацию о группе, ее участниках, чистит списки от ботов. Кроме того, доступны уже готовые базы, собранные другими пользователями. Часть за деньги, другие бесплатно.

Pepper.Ninja
Размещается на одноименном сайте — https://pepper.ninja/ — и предлагает свои услуги по цене от 490 рублей в месяц. Этот парсер более универсален. С его помощью можно работать не только ВКонтакте , но и в Инстаграме, Фейсбуке, Одноклассниках. Еще одна особенность: можно сразу задать много заданий, которые будут выполняться с некоторой периодичностью.
Для тех, кто не уверен в своих силах или пока не может разобраться, что к чему, имеется официальная группа ВКонтакте и блог. Там вам все подробно расскажут и объяснят.

Фонарик
Живет программа со столь милым названием на сайте spotlight.svezet.ru и безумно радует своей ценой. Этот парсер полностью бесплатен. Хорош для новичков, кто только постигает азы. Простой интерфейс, небольшой, базовый, но хороший и гармоничный перечень возможностей. Еще и уведомления об активностях в группах всегда пришлет.
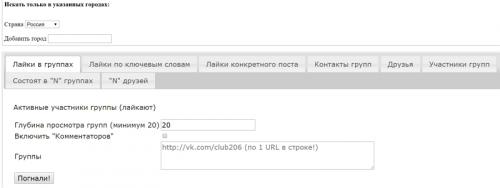
Фонарик
«Барков.нет»
Искать програмку вам предстоит на сайте vk.barkov.net . Довольно удобно решен вопрос оплатой. Базовыми функциями вы можете пользоваться бесплатно, а если решили углубиться в парсинг — выложите за доступ ко всем скриптам 149 рублей в день. Базовые параметры позволяют вполне бодро собирать аудиторию по основным параметрам, проводить анализ подписчиков сообщества. Ну а в расширенном виде вам и отдельно «соберут» данные о людях с открытой стеной и личными сообщениями, и номера телефонов укажут, если есть.
Segmento target
Его можно найти на сайте segmento-target.ru . Программа имеет полноценный пробный период — 7 дней. За это время точно можно разобраться, что к чему и решить, хотите вы платить за программу или нет. Далее цена будет варьироваться: от 60 рублей в день до 1500 рублей в месяц. Чем больший период оплатишь, тем больше “скидка”.
Работает парсер с ВКонтакте, а также с Инстаграмом и Одноклассниками. Помимо основных функций, умеет собирать номера телефонов, странички твиттера и имена в Скайпе, анализировать данные пользователей, которые приняли участие в тематическом опросе и т.д.

Да уж, здесь разработчики прямо своим названием сообщают, что у них за программа и для чего она. Скачать ее можно на сайте vkparser.ru . Правда, пробного периода у программы нет, и просит она сразу 900 рублей за месяц. Но «отрабатывает» эти деньги на совесть.
Собирает полноценные анкеты подписчиков (страна, город, возраст, пол). Также может указать номер телефона и поделиться с вами информацией о имеющихся у пользователей аккаунтах в Скайпе и Инстаграме.
TARGET-TRAINING
Для того, чтобы познакомиться с данным парсером, милости просим на сайт retarget.target-training.ru . Деньги с собой не берите, сервис полностью бесплатный.
Правда, с функционалом у программы беда. Она здесь, собственно, всего одна. Зато необычная. Она ищет ключевые слова на стенах пользователей. Довольно удобно для того, чтобы выделить людей, объединенных общей мыслью/вопросом/проблемой.
Парсинг сайтов python. Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкусудобнее и лаконичнее, так что, буду использовать ее.Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого . Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении . Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут ). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Парсинг в программировании это. Понятие парсинга данных
Парсинг представляет собой способ индексирования информации с ее дальнейшим преобразованием в другой формат, а в некоторых случаях даже другую разновидность данных.
Для примера возьмем HTML-файл. Парсинг позволит вам преобразовать информацию из этого файла в сплошной текст, тем самым сделав его читабельным. Другой вариант – трансформировать HTML в JSON для последующей работы в приложении или скрипте.
Однако в данной статье будет рассмотрена более узкая сфера применения парсинга – обработка данных на веб-страницах. Иными словами, парсинг предполагает сбор и систематизацию данных, которые находятся на сайте.

Понятие парсинга данных
Теперь о том, что такое парсер сайта. Это специальная программа, осуществляющая сбор нужной информации по заранее установленным критериям.
При этом парсинг является легальным видом деятельности. Законодательством установлен запрет на следующие сходные манипуляции:
- взлом веб-сайта – несанкционированное получение информации из аккаунтов пользователей и др.;
- DDOS-атаки – когда парсинг перегружает сайт;
- плагиат – незаконное использование фотографий с копирайтом, оформленных у нотариуса оригинальных текстов и т.п.
Парсинг является правомерным в том случае, если он осуществляет сбор данных из открытых источников. Такую информацию можно набрать и собственноручно, поэтому парсеры лишь упрощают эти многочисленные действия и повышают скорость их выполнения. Кроме того, сводятся к минимуму оплошности, присущие работе человека. Таким образом, в чистом парсинге нет никаких противозаконных деяний.
Парсинг питон. Что такое парсинг и с чем его едят
Парсинг (по-русски «синтаксический анализ») — это бессмертная задача разобрать и преобразовать в осмысленные единицы нечто, написанное на некотором фиксированном языке, будь то язык программирования, язык разметки, язык структурированных запросов или главный язык жизни, Вселенной и всего такого. Типичная последовательность этапов решения задачи выглядит примерно так:
- Описать язык . Конечно, сначала надо определиться, какую именно задачу мы решаем. Обычно описание языка — это очередная вариация формы Бэкуса-Наура . ( Вот , например, описание грамматики Python, использующееся при построении его парсера.) При этом устанавливаются как правила «построения предложений» в языке, так и правила определения валидных слов.
- Разбить ввод на токены . Пишется лексический анализатор (в народе токенайзер), который разбивает входную строку или файл на последовательность токенов , то есть валидных слов нашего языка (или ноет, что это нельзя сделать).
- Проверить синтаксис и построить синтаксическое дерево . Проверяем, соответствует ли последовательность токенов описанию нашего языка. Здесь в ход идут алгоритмы вроде метода рекурсивного спуска . Каждое валидное предложение языка включает какое-то конечное количество валидных слов или других валидных предложений; если токены смогли сложиться в стройную картину, то на выходе мы автоматически получаем дерево, которое и называется абстрактным синтаксическим деревом .
- Сделать, наконец, работу . У вас есть синтаксическое дерево и вы можете наконец сделать то, что хотели: посчитать значение арифметического выражения, организовать запрос в БД, скомпилировать программу, отобразить веб-страницу и так далее.