10 из лучших инструментов парсинга для.. Octoparse
- 10 из лучших инструментов парсинга для.. Octoparse
- Как парсить данные с сайта в excel. Парсер сайтов и файлов (парсинг данных с сайта в Excel)
- Парсинг сайтов законность. «Дело техники». Фантастические прокси и где они обитают.
- Парсинг сайтов c#. Учимся парсить сайты на C#: часть 1
- Библиотеки для парсинга Python. Инструменты
- Сайты для парсинга. Законно ли парсить сайты
- Библиотеки для парсинга js. По используемому фреймворку
- Как парсить данные с сайта Python. Парсинг страниц на Python. Parser на Python
10 из лучших инструментов парсинга для.. Octoparse
Лицензия: Бесплатная (общедоступная)
Сайт : https ://www.octoparse.com/
Octoparse – бесплатный и при этом мощный веб-парсер с понятными функциями, который используется для практически любых типов данных, которые вам могут понадобиться. Вы можете использовать Octoparse, чтобы разобрать сайт с помощью широкого функционала и ряда возможностей парсера.
Благодаря своему интерфейсу в стиле «наведи-и-кликни», Octoparse позволяет вам захватить весь текст с веб-сайта, так что вы можете скачать практически весь контент и сохранить его в структурированном формате Excel , HTML , CSV или своей собственной базе данных, при этом не прибегая к кодированию.
Как мы зарабатываем на ИТ — технологиях в России?
Вы можете извлечь данные с тяжелых веб-сайтов со сложной выдачей блоков данных, которые используют собственные встроенные инструменты Regex. Также можете выяснить местоположение веб-элементов, используя инструмент XPath. Вас больше не будут тревожить блокираторы IP , так как Octoparse предлагает IP-прокси серверы, которые автоматизируют процесс смены IP, пока те не замечены агрессивными веб-сайтами.
Кроме того, Octoparse предлагает использовать новую версию шаблонов задач, которая содержит готовые к использованию задания для извлечения данных с разных популярных веб-сайтов вроде Amazon , Yelp, Tripadvisor и т.д.Плюсы: Octoparse – лучший бесплатный парсер данных, который мне встречался. Бесплатная версия дает возможность использовать наиболее мощный функционал с ограниченными страницами для парсинга, если сравнивать с другими инструментами для парсинга данных, которые будут описаны дальше. Цена премиум-версии Octoparse конкурентоспособная. Используя шаблоны задач, вам нужно только ввести параметры (указать URL страницы, ключевые слова для поиска и т.д.) и ждать, пока данные автоматически парсятся.
Минусы: К сожалению, Octoparse не может парсить данные из PDF-файлов. Так же как не может скачивать изображения напрямую, хотя и дает возможность извлекать URL этих изображений.
Как парсить данные с сайта в excel. Парсер сайтов и файлов (парсинг данных с сайта в Excel)
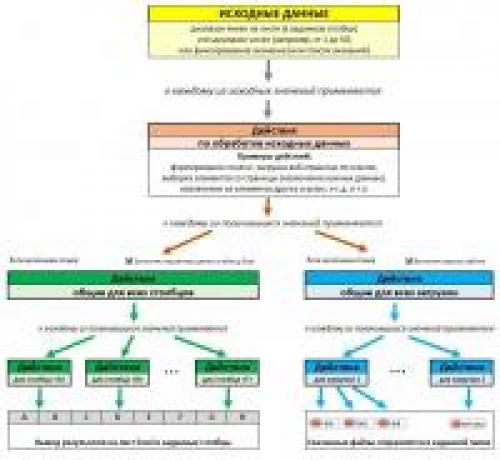
Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей. Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
В программе можно настроить несколько парсеров (обработчиков сайтов).Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Настройка программы, - дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт - от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,нажимаете кнопку, - и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Парсинг сайтов законность. «Дело техники». Фантастические прокси и где они обитают.
Как естественна сама идея парсинга (всегда интересно поглядеть, что там у «соседей» происходит), так же просты и базовые способы его реализации. Если хочешь узнать — спроси, но, если хочется знать актуальные значения большого массива данных (будь то цены на товары, их описания, доступные для заказа объёмы или горячие скидки), то «спрашивать» придется много и часто. Понятно, что никому и в голову не придет пытаться собирать эти данные вручную (разве что большой бригаде трудолюбивых ребят из южных стран, вдохновленных не самым гуманным способом), поэтому в ход идут простые действенные решения в лоб: «сваять» сайт, настроить браузер, собрать ботов — и «простукиваем» целевой сайт на предмет интересующих показателей, ответы тщательно записываем в «блокнот» удобного формата, собранные данные анализируем, повторяем.Вот некоторые подходы к «технике парсинга» от наших читателей и от нас:
- «Ферма Selenium — и вперёд!» (Имеются в виду headless-браузеры с BeautifulSoup-подобным, как у Selenium/Splinter, решением). Как говорит наш читатель, он написал маленький сайт на кластере docker swarm жене для мониторинга сайтов продавцов (она импортер), чтобы те не нарушали политику по ррц/мрц (рекомендуемые розничные цены). По отзывам автора, всё работает стабильно, экономика парсинга сходится — «все затраты это 4 ноды по 3$». Правда, товаров у гордого автора всего около тысячи и сайтов в парсинге десяток, не больше :)
- «Запускаем Хромиум и все ОК, получается 1 товар в 4-5 секунд можно брать…». Ясное дело, что ни один админ не обрадуется подскочившей нагрузке на сервер. Сайт, конечно, для того и нужен, чтобы предоставлять информацию всем интересующимся, но «вас много, а я один», поэтому особо рьяно интересующихся, само собой, игнорируют. Что ж, не беда: на помощь приходит Chromium — если браузер стучится на сайт в режиме «нам только спросить» — ему можно и без очереди. Ведь в общем массиве задач парсинга в 90% случаев делается парсинг html-страниц, а в «особо тяжких случаях» (когда сайты активно защищаются, как тот же Яндекс.Маркет, просящий капчу) справляется именно Chromium.
- «Чистые прокси своими руками из LTE-роутеров/модемов». Есть вполне рабочие способы настроить чистые прокси, годные для парсинга поисковых систем: ферма 3G/4G-модемов либо покупка прокси «белых» вместо набора случайных «грязных» прокси-серверов. Тут важно, какой язык программирования используется для такого промышленного парсинга — 300 сайтов в день (и правильный ответ — .Net! :). На самом деле, в Интернете полно сайтов с открытыми списками прокси, 50% из которых вполне рабочие и с этих сайтов не так уж сложно парсить списки прокси, чтобы потом с их помощью парсить другие сайты :)… Ну мы так делаем.
- Ещё один кейс в пользу Selenium: «Сам занимаюсь парсингом (но не в рунете, а ловлю заказы на любимом всеми upwork.com, там это обычно зовётся scraping, более подходящий термин, имхо). У меня немного другое соотношение, где-то 75 к 25. Но в целом да, если лень или сложно — то уж от selenium пока никто не уворачивался :) Но из нескольких сотен сайтов, с которыми приходилось работать, ни разу не доходило до распознавания картинок, чтоб получить целевые данных. Обычно, если данных нет в html, от они всегда подтягиваются в каком-нибудь json (ну, собственно, ниже уже показали пример).
- «Укротители Python-ов». И ещё кейс читателя: «На прошлой работе использовал Python/Scrapy/Splash для 180+ сайтов в день разного размера от prisma.fi и verkkokauppa.com до какой-то мелочи с 3-5 продуктами. В конце прошлого года арендовали у Hetzner вот такой сервер (https://www.hetzner.com/dedicated-rootserver/ax60-ssd) с Ubuntu Server на борту. Большая часть вычислительных ресурсов пока что простаивает.
- «WebDriver — наше всё». Занимаясь в целом автоматизацией (куда уже и парсинг попадает), настолько достоверной, на сколько это возможно (задачи QA). Хорошая рабочая станция, десяток-другой браузеров параллельно — на выходе очень злая-быстрая молотилка.
Парсинг сайтов c#. Учимся парсить сайты на C#: часть 1
Данная статья первая из цикла "Парсим сайты на C#". В ней мы научимся непосредственно подключаться к выбранному серверу, скачивать страничку, разбирать её исходный код, а также выводить на экран первоначальный результат. Эта программа только для тестов – для реальной работы я рекомендую использовать готовые библиотеки. Однако даже без библиотек, встроенными средствами NET несложно сделать настоящее приложение - парсер для сайтов самостоятельно.Итак, начнем мы с того, что научимся получать страничку. В данном случае пациентом выступает рейтинг топ лиру, конкретно страница с адресом "https://www.liveinternet.ru/?upread.ru" - именно в этом ареале в настоящий момент обитает мой блог. Эту страницу мы скачиваем, ищем на ней адрес "upread.ru" (парсим) и выводим место, на котором данный сайт находится. На выходе будет примерно такая картинка.А вот и сам код программы:Библиотеки для парсинга Python. Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкусудобнее и лаконичнее, так что, буду использовать ее.Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого . Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении . Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут ). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Сайты для парсинга. Законно ли парсить сайты
Если кратко, то законно — если вы парсите информацию, которая есть в открытом доступе. Это логично, ведь так любой человек и без парсера может собрать интересующие данные. Что преследуется законом:
- парсинг с целью DDOS-атаки;
- сбор личных данных пользователей, которые находятся не на виду — например, в личном кабинете, указывались при регистрации и т. д.;
- парсинг для воровства контента — например, перепост чужих статей под своим именем, использование авторских фото не из бесплатных стоков;
- сбор информации, которая составляет государственную или коммерческую тайну.
Рассмотрим это подробнее с точки зрения законодательства Украины.
Согласно , информация по режиму доступа делится на общедоступную и информацию с ограниченным доступом. В свою очередь информация с ограниченным доступом делится на конфиденциальную, гостайну и служебную. Определения каждого вида содержатся в .
В большей степени любой спор касательно незаконного парсинга и/или распространения информации касается именно конфиденциальных данных.
- Информация о физлице, которая может его идентифицировать, априори является конфиденциальной и может быть использована только по согласию. Поэтому, чтобы парсинг был законным, парсить нужно либо деперсонифицированные данные, либо получать согласие распорядителя информации — владельца сайта, на котором зарегистрирован пользователь.
- Если речь идет об информации, не являющейся персональной, она может считаться конфиденциальной, только если ее владелец определил ее как таковую. Так, чаще всего на сайтах размещается либо политика конфиденциальности, либо правила пользования сайтом. В этом документе/на этой странице указаны права и обязанности посетителей/пользователей, которые нужно соблюдать. Поэтому перед парсингом стоить проверить, не запрещен ли сбор информации и использование данных сайта.
Также важным является возможное нарушение авторских установленных и ГКУ . Перед парсингом нужно понимать, что любой тип контента защищен авторским правом с момента его создания. И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
Даже при условии правомерности парсинга, его осуществление не должно подрывать нормальную работу сайта, который парсят. Если из-за парсинга информации произойдет сбой и утечка или подделка данных, то подобные действия могут расцениваться как несанкционированное вмешательство в работу сайта, что является нарушением согласно .
Есть еще один нюанс. Представим, что одна компания долго разрабатывала продукт, вкладывала деньги, чтобы собрать базу пользователей или покупателей, а другая спарсила все и за несколько недель создала практически аналогичный сервис или продукт. Подобные действия при наличии весомой доказательной базы могут расцениваться как нарушение условий конкуренции согласно .
Библиотеки для парсинга js. По используемому фреймворку
Если задачи, стоящие при сборе данных нестандартные, нужно выстроить подходящую архитектуру, работать с множеством потоков, и существующие решения вас не устраивают, нужно писать свой собственный парсер. Для этого нужны ресурсы, программисты, сервера и специальный инструментарий, облегчающий написание и интеграцию парсинг программы, ну и конечно поддержка (потребуется регулярная поддержка, если изменится источник данных, нужно будет поменять код). Рассмотрим какие библиотеки существуют в настоящее время. В этом разделе не будем оценивать достоинства и недостатки решений, т.к. выбор может быть обусловлен характеристиками текущего программного обеспечения и другими особенностями окружения, что для одних будет достоинством для других – недостатком.
Парсинг сайтов Python
Библиотеки для парсинга сайтов на Python предоставляют возможность создания быстрых и эффективных программ, с последующей интеграцией по API. Важной особенностью является, что представленные ниже фреймворки имеют открытый исходный код.– наиболее распространенный фреймворк, имеет большое сообщество и подробную документацию, хорошо структурирован.Лицензия: BSD– предназначен для анализа HTML и XML документов, имеет документацию на русском, особенности – быстрый, автоматически распознает кодировки.Лицензия: Creative Commons, Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0)– мощный и быстрый, поддерживает Javascript, нет встроенной поддержки прокси.Лицензия: Apache License, Version 2.0– особенность – асинхронный, позволяет писать парсеры с большим количеством сетевых потоков, есть документация на русском, работает по API.Лицензия: MIT License– простая и быстрая при анализе больших документов библиотека, позволяет работать с XML и HTML документами, преобразовывает исходную информацию в типы данных Python, хорошо документирована. Совместима с BeautifulSoup, в этом случае последняя использует Lxml как парсер.Лицензия: BSD– инструментарий для автоматизации браузеров, включает ряд библиотек для развертывания, управления браузерами, возможность записывать и воспроизводить действия пользователя. Предоставляет возможность писать сценарии на различных языках, Java, C#, JavaScript, Ruby.Лицензия: Apache License, Version 2.0JavaScript также предлагает готовые фреймворки для создания парсеров с удобными API.— это headless Chrome API для NodeJS программистов, которые хотят детально контролировать свою работу, когда работают над парсингом. Как инструмент с открытым исходным кодом, Puppeteer можно использовать бесплатно. Он активно разрабатывается и поддерживается самой командой Google Chrome. Он имеет хорошо продуманный API и автоматически устанавливает совместимый двоичный файл Chromium в процессе установки, а это означает, что вам не нужно самостоятельно отслеживать версии браузера. Хотя это гораздо больше, чем просто библиотека для парсинга сайтов, она очень часто используется для парсинга данных, для отображения которых требуется JavaScript, она обрабатывает скрипты, таблицы стилей и шрифты, как настоящий браузер. Обратите внимание, что хотя это отличное решение для сайтов, которым для отображения данных требуется javascript, этот инструмент требует значительных ресурсов процессора и памяти.Лицензия: Apache License, Version 2.0– быстрый, анализирует разметку страницы и предлагает функции для обработки полученных данных. Работает с HTML, имеет API устроенное так же, как API jQuery.Лицензия: MIT License– является библиотекой Node.js, позволяет работать с JSON, JSONL, CSV, XML,XLSX или HTML, CSS. Работает с прокси.Лицензия: Apache License, Version 2.0– написан на Node.js, ищет и загружает AJAX, поддерживает селекторы CSS 3.0 и XPath 1.0, логирует URL, заполняет формы.Лицензия: MIT LicenseJava также предлагает различные библиотеки, которые можно применять для парсинга сайтов.– библиотека предлагает легкий headless браузер (без графического интерфейса) для парсинга и автоматизации. Позволяет взаимодействовать с REST API или веб приложениями (JSON, HTML, XHTML, XML). Заполняет формы, скачивает файлы, работает с табличными данными, поддерживает Regex.Лицензия: Apache License (Срок действия программного обеспечения истекает ежемесячно, после чего должна быть загружена самая последняя версия)– библиотека для работы с HTML, предоставляет удобный API для получения URL-адресов, извлечения и обработки данных с использованием методов HTML5 DOM и селекторов CSS. Поддерживает прокси. Не поддерживает XPath.Лицензия: MIT License– не является универсальной средой для модульного тестирования, это браузер без графического интерфейса. Моделирует HTML страницы и предоставляет API, который позволяет вызывать страницы, заполнять формы, кликать ссылки. Поддерживает JavaScript и парсинг на основе XPath.Лицензия: Apache License, Version 2.0– простой парсер, позволяет анализировать HTML документы и обрабатывать с помощью XPath.Как парсить данные с сайта Python. Парсинг страниц на Python. Parser на Python
Рано или поздно любой Python-программист сталкивается с задачей скопировать какой-нибудь материал с сайта. Так как страниц на нём достаточно много, терять время на ручное копирование — не самый лучший выход.
Парсер — что это вообще такое?
Если вы ещё не сталкивались с этим понятием, то давайте поговорим о нём подробнее. Итак, парсером называют скрипт , который осуществляет синтаксический анализ данных с последующих их отбором и группировкой в БД либо электронную таблицу. Эта программа выполняет сопоставление линейной последовательности слов с учётом правил языка.
Алгоритм работы парсера: 1. Получение доступа к сети и API веб-ресурса, его скачивание. 2. Извлечение, исследование и обработка скачанных данных. 3. Экспорт полученной информации.
По сути, парсинг может проводиться с применением разных языков программирования, но проще всего показать его именно на Python , благодаря простому синтаксису.
Что касается назначения парсинга, то он используется в разных целях, например: — сбор информации для своего сайта; — индексация веб-страниц; — получение данных, не являющихся интеллектуальной собственностью и т. д.
Но чтобы парсер полноценно выполнил поставленные задачи, нужно подготовить среду, о чём и поговорим.
Готовим к работе скрипт парсинга на Python
Подготовка включает в себя 2 этапа: сначала мы должны освежить свои знания в некоторых областях, а потом можно приступить и к подготовке библиотек.
Итак, для успешного парсинга вам потребуются: 1. Знание PHP, HTML, CSS, JavaScript. Они нужны для первичного анализа и понимания кода страницы, с которой и будем осуществлять парсинг. Не стоит думать, что всё так просто, ведь порой и опытный специалист не может разобраться в структуре сайта, написанного на HTML. 2. Знание и понимание, как применять библиотеки HTML-парсинга на Python, а также регулярные выражения. Это поможет разобраться с проблемами, связанными с невалидным кодом. 3. Основы объектно-ориентированного программирования (желательно). 4. Знания баз данных, например, MySQL. Это необходимо для обработки выходных данных.
Вышеперечисленное — базис, владея которым HTML-парсинг не вызовет у вас затруднений. Также было бы неплохо уметь работать с иерархическими структурами, XML и JSON.
Переходим ко второй части — библиотекам. Вот основные: — LXML. Пакет, имеющий поддержку XLST и XPath. Отличается богатым функционалом по обработке разных API; — GRAB. Очень распространённый инструмент, работает с DOM, может выполнять автозаполнение форм, обрабатывать перенаправление с сайтов; — Beautiful Soup. Прекрасно справляется со структурным разбором сайта, а также с обработкой невалидного кода HTML.
Устанавливаем библиотеку Beautiful Soup (Linux)
Прекрасным преимуществом этой библиотеки является наличие персонального алгоритма структурирования HTML-кода. А это уже позволяет сэкономить разработчику время, что не может не радовать. Итак, устанавливаем:
Установив нужные модули, можем парсить сайт . В результате мы получим его структурированный код:
Чтобы выполнить поиск по ссылкам:
А вот так работает парсер DIV-блоков:
Если хотим получить ссылки на изображения:
Как видим, ничего сложного нет. Но если хотите узнать больше, вы всегда можете записаться на курс « Разработчик Python » в OTUS!