Как использовать прокси для парсера Xpath + php. Правовые аспекты при использовании прокси во время парсинга
- Как использовать прокси для парсера Xpath + php. Правовые аспекты при использовании прокси во время парсинга
- Парсинг html. Браузерные движки
- Парсер сайтов в excel. Каталог парсеров — Страница 2
- Как сделать парсер на Python. Инструменты
- Парсер Python для чайников. Модуль запросов
- Как парсить данные с сайта Python. Учимся парсить веб-сайты на Python + BeautifulSoup
- Парсинг -- это. Основные понятия
- Библиотеки для парсинга Python. Python
Как использовать прокси для парсера Xpath + php. Правовые аспекты при использовании прокси во время парсинга
На данном этапе у вас должно быть хорошее представление о том, что такое прокси-серверы и как выбрать лучший вариант для вашего веб-проекта. Тем не менее, есть один аспект, который многие люди упускают из виду, когда речь заходит о парсинге и прокси, — это юридический аспект. Использование прокси-IP-адреса для посещения веб-сайта законно, однако, необходимо помнить о нескольких моментах, чтобы не попасть в серую зону. Наличие надежного прокси-решения похоже на обладание суперсилой, однако оно может сделать вас беспечным. Имея возможность отправлять огромное количество запросов на веб-сайт, оставаясь анонимными, люди начнут этим злоупотреблять и перегружать серверы веб-сайта слишком большим количеством запросов. Что, естественно, делать не стоит. Если вы используете парсер, то вы всегда должны с уважением относиться к веб-сайтам, которые вы сканируете. Независимо от масштаба или сложности вашего проекта, вы всегда должны следовать рекомендациям по парсингу веб-страниц (Скоро выйдет руководство по использованию парсеров) и следить, чтобы ваши боты не перегружали веб-сайты. Кроме того, если веб-сайт информирует вас (или сообщает прокси-провайдеру) о том, что ваш парсер мешает работе сайта или сайта нежелателен, вы должны ограничить количество запросов или прекратить сканирование. Пока вы соблюдаете правила, вероятность того, что вы столкнетесь с какими-либо юридическими проблемами, гораздо ниже. Как упомянуто в нашем Руководстве по веб-парсерам для , есть еще один важный юридический вопрос, касающийся использования домашних или мобильных IP-адресов: а есть ли у вас явное согласие их владельцев на использование этих адресов для парсинга веб-страниц? Поскольку GDPR определяет IP-адреса как информацию, позволяющую установить личность, вам необходимо убедиться, что все IP-адреса ЕС, которые вы используете в качестве прокси-серверов, соответствуют GDPR. Это означает, что вам нужно убедиться, что владелец этого IP-адреса дал свое явное согласие на использование своего домашнего или мобильного IP-адреса в качестве прокси-сервера для парсинга. Если у вас есть собственный IP-адрес, то вам нужно будет самостоятельно обработать это согласие. Однако если вы получаете прокси от стороннего поставщика, то прежде чем использовать их для парсинга, вам необходимо убедиться, что у него есть такое согласие и оно соответствуют GDPR.
Парсинг html. Браузерные движки
Движок браузера — основной компонент каждого крупного браузера. Его основная роль — объединить структуру (HTML) и стиль (CSS), чтобы отобразить страницу на экране. Он также отвечает за выяснение того, какие фрагменты кода интерактивны. Не думайте о нем как об отдельном ПО. Скорее, это часть более крупного ПО — в нашем случае, браузера.
В мире много таких движков. Но у большинства браузеров один из трех полных, над которыми идет активная работа:
Gecko. Разработан компанией Mozilla для браузера Firefox. Кроме него, сейчас движок Gecko используют ещё в Tor и Waterfox. Написан на C++ и Rust.
WebKit. В основном его разработала компания Apple для Safari. На нем также работают браузеры GNOME Web (Epiphany) и Otter. Интересно, что все браузеры на iOS, включая Firefox и Chrome, работают на WebKit. Он написан на C++.
Blink, часть Chromium. Разрабатывает компания Google на основе кода WebKit для браузера Chrome. На нем также работают браузеры Edge, Brave, Silk, Vivaldi, Opera и большинство других проектов браузеров, некоторые через QtWebEngine. Написан на C++.
С этим понятно. Теперь посмотрим, что произойдет после получения первого HTML-документа с сервера. Предположим, документ выглядит так:
This is a paragraph. This is another paragraph,
This is my page
This is a H3 header.
Даже если HTML-код страницы запроса больше исходного пакета 14 КБ, браузер начнет парсинг и попытается отобразить результат на основе имеющихся данных.
HTML-парсинг включает два этапа: токенизацию и построение DOM-дерева. Document Object Model – объектная модель документа.
Парсер сайтов в excel. Каталог парсеров — Страница 2
в этом каталоге вы можете найти готовый парсер для интересующего вас сайта, а также посмотреть примеры настройки парсера под разные задачи для изучения способов настройки программы.
Парсинг электротоваров с сайта directelectric.ru
Получить список всех товаров сайта directelectric.ru, с последующим выводом данных в эксель.
Парсинг интернет-магазина светильников bclight.ru
Пройтись по категориям сайта bclight.ru с последующим выводом всех товаров в эксель.
Парсинг сайта мототехники atvtrade.ru
Перейти на каждую из категорий сайта atvtrade.ru, вывести данные в эксель и скачать изображения товаров под именами артикулов.
Парсинг отфильтрованных данных с сайта lunda.ru
Пользователь путем выставления нужных фильтров на сайте lunda.ru, получает ссылку на результат. По заданной ссылке спарсить все товары.
Парсинг отфильтрованных данных с сайта fastbox.su
Пользователь путем выставления нужных фильтров на сайте fastbox.su, получает ссылку на результат. По заданной ссылке спарсить все товары и изображения к ним.
Парсер каталога товаров world-gadgets.ru
Загрузить данные с сайта world-gadgets.ru, с возможностью выбора нужной категории. Скачать фото товаров в локальную папку на ПК.
Парсер данных с сайта techport.ru
Спарсить товары с сайта techport.ru из раздела встраиваемая бытовая техника. Полученные данные вывести на лист эксель.
Парсинг данных с сайта русскаядымка.рф
Пройтись по структуре сайта русскаядымка.рф, получить список всех товаров с последующим выводом результатов в эксель файл.
Получение списка музыкального оборудования сайта pop-music.ru
Авторизоваться на сайте pop-music.ru, получить список доступного оборудования, вывод данных в эксель.
Парсинг музыкальных инструментов с сайта dynatone.ru
1. Авторизоваться на сайте dynatone.ru, пройтись по каталогу музыкальных инструментов и перенести необходимые данные в эксель. 2. Скачать изображения товаров, сохранив их под номерами артикулов.
Как сделать парсер на Python. Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкусудобнее и лаконичнее, так что, буду использовать ее.Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого . Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении . Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут ). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Парсер Python для чайников. Модуль запросов
Библиотека запросов используется для выполнения HTTP-запросов к определенному URL-адресу и возвращает ответ. Запросы Python предоставляют встроенные функции для управления как запросом, так и ответом.
Установка
Установка запросов зависит от типа операционной системы, основная команда в любом месте — открыть командный терминал и запустить,
pip install requests
Сделать запрос
Модуль запросов Python имеет несколько встроенных методов для выполнения HTTP-запросов к указанному URI с использованием запросов GET, POST, PUT, PATCH или HEAD. HTTP-запрос предназначен либо для получения данных из указанного URI, либо для отправки данных на сервер. Он работает как протокол запроса-ответа между клиентом и сервером. Здесь мы будем использовать запрос GET.
Метод GET используется для получения информации с заданного сервера с использованием заданного URI. Метод GET отправляет закодированную информацию о пользователе, добавленную к запросу страницы.
Пример: запросы Python, выполняющие запрос GET
Python3
importrequests
# Making a GET request
r=requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Вывод:
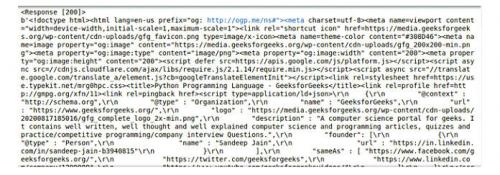
Объект ответа
Когда кто-то делает запрос к URI, он возвращает ответ. Этот объект Response в терминах python возвращается с помощью request.method (), являющегося методом — get, post, put и т.д. Response — это мощный объект с множеством функций и атрибутов, которые помогают в нормализации данных или создании идеальных частей кода. Например, response.status_code возвращает код состояния из самих заголовков, и можно проверить, был ли запрос обработан успешно или нет.
Объекты ответа могут использоваться для обозначения множества функций, методов и функций.
Как парсить данные с сайта Python. Учимся парсить веб-сайты на Python + BeautifulSoup
Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием(Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал:.
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.
Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4 . Их устанавливаем через терминал при помощи команд:
и
После чего пишем следующий код:
Тут мы импортируем новые библиотеки. URL это строка, она содержит ссылку на сайт. При помощи requests.get мы совершаем запрос к веб страничке. Сама функция возвращает ответ от сервера (200, 404 и т.д.), а page.content предоставляет нам полный код загруженной страницы. Тот же код, который мы видели в инспекторе.
Парсинг -- это. Основные понятия
Перед разговором по теме стоит определиться с основными понятиями, чтобы не было разночтений. Это глоссарий данной статьи. Он может совпадать с общепринятой терминологией, но вообще говоря, не обязан, поскольку показывает картину, формирующуюся в голове автора.Итак:
- входной символьный поток (далее входной поток или поток ) — поток символов для разбора, подаваемый на вход парсера
- parser/парсер ( разборщик, анализатор ) — программа, принимающая входной поток и преобразующая его в AST и/или позволяющая привязать исполняемые функции к элементам грамматики
- AST (Abstract Syntax Tree)/ АСД (Абстрактное синтаксическое дерево) ( выходная структура данных ) — Структура объектов, представляющая иерархию нетерминальных сущностей грамматики разбираемого потока и составляющих их терминалов . Например, алгебраический поток (1 + 2) + 3 можно представить в виде ВЫРАЖЕНИЕ(ВЫРАЖЕНИЕ(ЧИСЛО(1) ОПЕРАТОР(+) ЧИСЛО(2)) ОПЕРАТОР(+) ЧИСЛО(3)). Как правило, потом это дерево как-то обрабатывается клиентом парсера для получения результатов (например, подсчета ответа данного выражения)
- CFG (Context-free grammar)/ КСГ (Контекстно-свободная грамматика) — вид наиболее распространенной грамматики, используемый для описания входящего потока символов для парсера (не только для этого, разумеется). Характеризуется тем, что использование её правил не зависит от контекста (что не исключает того, что она в некотором роде задает себе контекст сама, например правило для вызова функции не будет иметь значения, если находится внутри фрагмента потока, описываемого правилом комментария). Состоит из правил продукции, заданных для терминальных и не терминальных символов.
- Терминальные символы ( терминалы ) — для заданного языка разбора — набор всех (атомарных) символов, которые могут встречаться во входящем потоке
- Не терминальные символы ( не терминалы ) — для заданного языка разбора — набор всех символов, не встречающихся во входном потоке, но участвующих в правилах грамматики.
- язык разбора (в большинстве случаев будет КСЯ ( контекстно-свободный язык )) — совокупность всех терминальных и не терминальных символов, а также КСГ для данного входного потока. Для примера, в естественных языках терминальными символами будут все буквы, цифры и знаки препинания, используемые языком, не терминалами будут слова и предложения (и другие конструкции, вроде подлежащего, сказуемого, глаголов, наречий и т.п.), а грамматикой собственно грамматика языка.
- BNF (Backus-Naur Form, Backus normal form)/ БНФ (Бэкуса-Наура форма) — форма, в которой одни синтаксические категории последовательно определяются через другие. Форма представления КСГ, часто используемая непосредственно для задания входа парсеру. Характеризуется тем, что определяемым является всегда ОДИН нетерминальный символ. Классической является форма записи вида:
::= | | . . . |Так же существует ряд разновидностей, таких как ABNF(AugmentedBNF), EBNF(ExtendedBNF) и др. В общем, эти формы несколько расширяют синтаксис обычной записи BNF. - LL(k), LR(k), SLR,… — виды алгоритмов парсеров. В этой статье мы не будем подробно на них останавливаться, если кого-то заинтересовало, внизу я дам несколько ссылок на материал, из которого можно о них узнать. Однако остановимся подробнее на другом аспекте, на грамматиках парсеров. Грамматика LL/LR групп парсеров является BNF, это верно. Но верно также, что не всякая грамматика BNF является также LL(k) или LR(k). Да и вообще, что значит буква k в записи LL/LR(k)? Она означает, что для разбора грамматики требуется заглянуть вперед максимум на k терминальных символов по потоку. То есть для разбора (0) грамматики требуется знать только текущий символ. Для (1) — требуется знать текущий и 1 следующий символ. Для (2) — текущий и 2 следующих и т.д. Немного подробнее о выборе/составлении BNF для конкретного парсера поговорим ниже.
Библиотеки для парсинга Python. Python
Библиотеки на Python предоставляют множество эффективных и быстрых функций для парсинга. Многие из этих инструментов можно подключить к готовому приложению в формате API для создания настраиваемых краулеров. Все перечисленные ниже проекты имеют открытый исходный код.
BeautifulSoup
Пакет для анализа документов HTML и XML, преобразующий их в синтаксические деревья. Он использует HTML и XML-парсеры, такие как html5lib и Lxml, чтобы извлекать нужные данные.
Для поиска конкретного атрибута или текста в необработанном HTML-файле в BeautifulSoup есть удобные функции find(), find_all(), get_text() и другие. Библиотека также автоматически распознаёт кодировки.
Установить последнюю версию BeautifulSoup можно через easy_install или pip:
easy_install beautifulsoup4
pip install beautifulsoup4
Selenium
Инструмент , который работает как веб-драйвер: открывает браузер, выполняет клики по элементам, заполняет формы, прокручивает страницы и многое другое. Selenium в основном используется для автоматического тестирования веб-приложений, но его вполне можно применять и для скрейпинга. Перед началом работы необходимо установить драйверы для взаимодействия с конкретным браузером, например ChromeDriver для Chrome и Safari Driver для Safari 10.
Установить Selenium можно через pip:
pip install selenium
Lxml
Библиотека с удобными инструментами для обработки HTML и XML файлов. Работает с XML чуть быстрее, чем Beautiful Soup, при этом используя аналогичный метод создания синтаксических деревьев. Чтобы получить больше функциональности, можно объединить Lxml и Beautiful Soup, так как они совместимы друг с другом. Beautiful Soup использует Lxml как парсер.
Ключевые преимущества библиотеки — высокая скорость анализа больших документов и страниц, удобная функциональность и простое преобразование исходной информации в типы данных Python.