Простой парсер товаров с amazon с помощью BeautifulSoup. Туториал по библиотеке BeautifulSoup4
- Простой парсер товаров с amazon с помощью BeautifulSoup. Туториал по библиотеке BeautifulSoup4
- Парсинг сайтов python. Часть 1
- Как сделать парсер. Какие сложности могут возникнуть при парсинге веб-сайтов?
- Парсинг habr. Превращение кода в AST
- Скрапинг python. Python web scraping tutorial (with examples)
- Библиотеки для парсинга python. Python
- Beautifulsoup python. Обзор Beautiful Soup
Простой парсер товаров с amazon с помощью BeautifulSoup. Туториал по библиотеке BeautifulSoup4
Парсеры — это программы, которые скачивают из интернета странички и разбирают их на составляющие: заголовок, картинка, текст… С помощью него можно выкачать с сайта гигабайты полезной информации. Библиотека BeautifulSoup4 как раз предназначена для парсинга.
В этой статье вы узнаете как распарсить. Цель : по ссылке на пост вытащить его название, текст и картинку.
Франк Сонненберг — известный американский писатель и коуч. За свои книги он попал в “Топ 100 Американских мыслителей”, а его блог принадлежит списку “Лучшие блоги о лидерстве 21 века”.
Прежде чем начинать…
Для прохождения этого туториала вам понадобятся 3 библиотеки:
$ pip install requests BeautifulSoup4 lxml
Получить страничку поста
Будем парсить пост “”. Чтобы распарсить HTML-страничку с постом, сначала нужно её скачать. Это можно сделать с помощьюrequests, вотоб этой библиотеке.
Здесь мы просто сделали запрос по ссылке и получили в ответ огромный HTML. Начинаться он будет примерно так:
Парсинг поста
У вас есть HTML страничка, но как достать оттуда заголовок поста, картинку и текст? Наконец, на сцену выходит BeautifulSoup . Сейчас вы получили HTML изresponse.text, но это просто строка с HTML кодом. Для работы с библиотекой BeautifulSoup нужно сделать из этой строки HTML-суп
суп — это новый объект с кучей возможностей. Например, теперь можно вывести HTML красиво, с отступами, с помощью методаsoup.prettify()
он называется исторически, вот. Если вкратце, то на самом деле верстальщики иногда косячат и, например, забывают закрывать теги или оставляют какие-нибудь неисправности. Такой код на HTML стали называтьtag soup. Браузеры умеют самостоятельно исправлять какие-то огрехи и делать из такого “супа” нормальный, рабочий HTML. Но если вы скачиваете страничку черезrequests, то браузер тут ни при чём, и вы получите такой HTML, какой написали верстальщики сайта, со всеми его ошибками.
Для этого и нужна библиотекаlxml, она подправит мелкие недочёты, и с ней BeautifulSoup справится даже с очень плохой вёрсткой. В этой строчке вы как раз говорите библиотеке BeautifulSoup использоватьlxml
.find(). Для начала нужно узнать в какой тег этот заголовок обёрнут. В этом помогут:
Итак, тегh1. Вот что вернёт метод.find():
Это тоже суп, но уже не со всей HTML-страницей, а только с этим тегом и тегами внутри него. Заголовка поста тут нет: пост называетсяAre You Grateful?, а такого текста в этом теге нет. Похоже, что это не тот тег, который вы искали. Их на странице несколько иBeautifulSoup4выдал первый, который нашёл. Это тег, который находится в самом верху страницы:
Как же найти заголовок поста, а не страницы? Можно уточнить запрос: заголовок поста лежит в теге:
Давайте попробуем такой запрос:
Тег нашли, а как достать его текст? Всё очень просто:
Победа, вы добрались до заголовка поста!
Картинка поста
Картинку можно найти так же: это единственный тегвнутри тега. Но давайте попробуем другой подход, найдём её по классу . У картинки есть классы:
У картинки есть 3 класса, они перечислены через пробел:
attachment-post-image size-post-image wp-post-image
Классattachment-post-imageпереводится как “Картинка поста”, а значит наверняка он есть только у картинок поста . Вот как найти тегimg, у которого есть такой класс:
soup . find ( 'img' , class_ = 'attachment-post-image' ) #
Тот же.find(), только указали параметрclass_. Нижнее подчёркивание разработчики библиотеки добавили для того, чтобы не было пересечения со словомclassиз Python, которое используется для создания классов.
Осталось достать адрес картинки, он лежит в аргументеsrc
find.
Парсинг сайтов python. Часть 1
Анализ данных предполагает, в первую очередь, наличие этих данных. Первая часть доклада рассказывает о том, что делать, если у вас не имеется готового/стандартного датасета, либо он не соответствует тому, каким должен быть. Наиболее очевидный вариант - скачать данные из интернета. Это можно сделать множеством способов, начиная с сохранения html-страницы и заканчивая Event loop (моделью событийного цикла). Последний основан на параллелизме в JavaScript, что позволяет значительно повысить производительность. В парсинге event loop реализуется с помощью технологии AJAX, утилит вроде Scrapy или любого асинхронного фреймворка.
Извлечение данных из html связано с обходом дерева, который может осуществляться с применением различных техник и технологий. В докладе рассматриваются три «языка» обхода дерева: CSS-селекторы, XPath и DSL. Первые два состоят в довольно тесном родстве и выигрывают за счет своей универсальности и широкой сфере применения. DSL (предметно-ориентированный язык, domain-specific language) для парсинга существует довольно много, и хороши они, в первую очередь, тем, что удобство работы с ним осуществляется благодаря поддержке IDE и валидации со стороны языка программирования.
Для тренировки написания пауков компанией ScrapingHub создан учебный сайт toscrape.com , на примере которого рассматривается парсинг книжного сайта. С помощью chrome-расширения SelectorGadget , которое позволяет генерировать CSS-селекторы, выделяя элементы на странице, можно облегчить написание скрапера.
Пример с использованием scrapy :
import scrapy
class BookSpider(scrapy.Spider):
name = 'books'
start_urls =
def parse(self, response):
for href in response.css('.product_pod a::attr(href)').extract():
url = response.urljoin(href)
print(url)
Пример без scrapy:
import json
from urllib.parse import urljoin
import requests
from parsel import Selector
index = requests.get('http://books.toscrape.com/')
books =
for href in Selector(index.text).css('.product_pod a::attr(href)').extract():
url = urljoin(index.url, href)
book_page = requests.get(url)
sel = Selector(book_page.text)
books.append({
'title': sel.css('h1::text').extract_first(),
'price': sel.css('.product_main .price_color::text')extract_first(),
'image': sel.css('#product_gallery img::attr(src)').extract_first()
})
with open('books.json', 'w') as fp:
json.dump(books, fp)
Некоторые сайты сами помогают парсингу с помощью специальных тегов и атрибутов html. Легкость парсинга улучшает SEO сайта, так как при этом обеспечивается большая легкость поиска сайта в сети.
Как сделать парсер. Какие сложности могут возникнуть при парсинге веб-сайтов?
- Веб-сайты со сложной структурой: большинство веб-страниц основаны на использовании HTML, и структура одной веб-страницы может сильно отличаться от структуры другой. Следовательно, когда вам нужно спарсить несколько веб-сайтов, для каждого из них придется создать свой парсер.
- Поддержка парсера может быть дорогой: веб-сайты всё время меняют дизайн веб-страницы. Если местоположение собираемых данных меняется, то программный код сборщиков данных необходимо снова доработать.
- Используемые веб-сайтами инструменты противодействия парсингу: такие инструменты позволяют веб-разработчикам управлять контентом, который отображается роботам и людям, а также ограничивать роботам возможность собирать данные на веб-сайте. Некоторые из методов защиты от парсинга: блокировка IP-адресов, captcha (Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматический тест Тьюринга для различения компьютеров и людей) и ловушки в виде приманок для парсеров.
- Необходимость авторизации: чтобы собрать во Всемирной паутине определенную информацию, возможно, вам сначала потребуется пройти авторизацию. Поэтому когда веб-сайт требует войти в систему, нужно убедиться, что парсер сохраняет файлы cookie, которые были отправлены вместе с запросом, чтобы веб-сайт воспринимал парсер в качестве авторизованного ранее посетителя.
- Медленная или нестабильная скорость загрузки: когда веб-сайты загружают контент медленно или не отвечают на запросы, может помочь обновление страницы, хотя парсер, возможно, не знает, что делать в такой ситуации.
Парсинг habr. Превращение кода в AST
Создание парсера это сложная задача. По сути, он должен брать кусок кода и превращать его в AST (абстрактное синтаксическое дерево). AST — структурированное представление программы в памяти, абстрактное — потому, что оно не содержит полной информации о коде, только семантику.находится в отдельной части.
Например, у нас есть следующий код:
sum = lambda(a, b) {
a + b;
};
print(sum(1, 2));
Наш парсер будет генерировать дерево, как JavaScript объект:
{
type: "prog",
prog: ,
body: {
// тело должно было быть "prog", но потому, что
// оно содержит только одно выражение, парсер
// превратил его в само выражение.
type: "binary",
operator: "+",
left: { type: "var", value: "a" },
right: { type: "var", value: "b" }
}
}
},
// вторая строка:
{
type: "call",
func: { type: "var", value: "print" },
args:
}>
}
>
}
Основная сложность в создании парсера состоит в сложности правильно организовать код. Парсер должен работать на более высоком уровне, чем чтение символов из строки. Несколько рекомендаций, чтобы уменьшить сложность кода:
- Писать много небольших функций. В каждой функции делать одну вещь и делать её хорошо.
- Не пробовать использовать регулярных выражений для парсинга. Они просто не работают. Они могут быть полезными в, но, для простоты, мы их использовать не будем.
- Не пробовать угадывать. Когда не уверены, как распарсить что-то, бросать исключение, содержащее местоположение ошибки (строка и колонка).
Скрапинг python. Python web scraping tutorial (with examples)
In this tutorial, we will talk about Python web scraping and how to scrape web pages using multiple libraries such as Beautiful Soup, Selenium, and some other magic tools like PhantomJS.
You’ll learn how to scrape static web pages, dynamic pages (Ajax loaded content), iframes, get specific HTML elements, how to handle cookies, and much more stuff. You will also learn about scraping traps and how to avoid them.
We will use Python 3.x in this tutorial, so let’s get started.
What is web scraping?
Web scraping generally is the process of extracting data from the web; you can analyze the data and extract useful information.
Also, you can store the scraped data in a database or any kind of tabular format such as CSV, XLS, etc., so you can access that information easily.
The scraped data can be passed to a library like NLTK for further processing to understand what the page is talking about.
Benefits of web scraping
You might wonder why I should scrape the web and I have Google? Well, we don’t reinvent the wheel here. It is not for creating search engines only.
You can scrape your competitor’s web pages and analyze the data and see what kind of products your competitor’s clients are happy with their responses. All this for FREE.
A successful SEO tool like Moz that scraps and crawls the entire web and process the data for you so you can see people’s interest and how to compete with others in your field to be on the top.
These are just some simple uses. The scraped data means making money :).
Install Beautiful Soup
I assume that you have some background in Python basics , so let’s install our first Python scraping library, which is Beautiful Soup.
To install Beautiful Soup, you can, or you can.
I’ll install it using pip like this:
$ pip install beautifulsoup4
To check if it’s installed or not, open your editor and type the following:
from bs4 import BeautifulSoup
Then run it:
$ python myfile.py
If it runs without errors, that means Beautiful Soup is installed successfully. Now, let’s see how to use Beautiful Soup.
Библиотеки для парсинга python. Python
Библиотеки на Python предоставляют множество эффективных и быстрых функций для парсинга. Многие из этих инструментов можно подключить к готовому приложению в формате API для создания настраиваемых краулеров. Все перечисленные ниже проекты имеют открытый исходный код.
BeautifulSoup
Пакет для анализа документов HTML и XML, преобразующий их в синтаксические деревья. Он использует HTML и XML-парсеры, такие как html5lib и Lxml, чтобы извлекать нужные данные.
Для поиска конкретного атрибута или текста в необработанном HTML-файле в BeautifulSoup есть удобные функции find(), find_all(), get_text() и другие. Библиотека также автоматически распознаёт кодировки.
Установить последнюю версию BeautifulSoup можно через easy_install или pip:
easy_install beautifulsoup4
pip install beautifulsoup4
Selenium
Инструмент , который работает как веб-драйвер: открывает браузер, выполняет клики по элементам, заполняет формы, прокручивает страницы и многое другое. Selenium в основном используется для автоматического тестирования веб-приложений, но его вполне можно применять и для скрейпинга. Перед началом работы необходимо установить драйверы для взаимодействия с конкретным браузером, например ChromeDriver для Chrome и Safari Driver для Safari 10.
Установить Selenium можно через pip:
pip install selenium
Lxml
Библиотека с удобными инструментами для обработки HTML и XML файлов. Работает с XML чуть быстрее, чем Beautiful Soup, при этом используя аналогичный метод создания синтаксических деревьев. Чтобы получить больше функциональности, можно объединить Lxml и Beautiful Soup, так как они совместимы друг с другом. Beautiful Soup использует Lxml как парсер.
Ключевые преимущества библиотеки — высокая скорость анализа больших документов и страниц, удобная функциональность и простое преобразование исходной информации в типы данных Python.
Beautifulsoup python. Обзор Beautiful Soup
HTML-содержимое веб-страниц можно проанализировать и очистить с помощью Beautiful Soup. В следующем разделе мы рассмотрим те функции, которые полезны для очистки веб-страниц.
Что делает Beautiful Soup таким полезным, так это множество функций, которые он предоставляет для извлечения данных из HTML. На этом изображении ниже показаны некоторые функции, которые мы можем использовать:
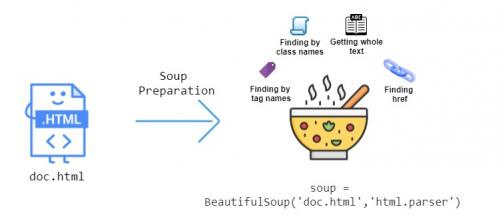
Давайте поработаем и посмотрим, как мы можем анализировать HTML с помощью Beautiful Soup. Рассмотрим следующую HTML-страницу, сохраненную в файл какdoc.html:
doc.html
Body's title line ends
Следующие фрагменты кода протестированы наUbuntu 20.04.1 LTS. Вы можете установить модульBeautifulSoup, набрав в терминале следующую команду:
pip3 install beautifulsoup4
HTML-файлdoc.htmlнеобходимо подготовить. Это делается путем передачи файла конструкторуBeautifulSoup, давайте воспользуемся для этого интерактивной оболочкой Python, чтобы мы могли мгновенно распечатать содержимое определенной части страницы:
from bs4 import BeautifulSoup
with open("doc.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
Теперь мы можем использовать Beautiful Soup для навигации по нашему веб-сайту и извлечения данных.
Переход к определенным тегам
Из объекта soup, созданного в предыдущем разделе, получим тег заголовкаdoc.html:
soup.head.title # returns
Вот разбивка каждого компонента, который мы использовали для получения названия:

Beautiful Soup - мощный инструмент, потому что наши объекты Python соответствуют вложенной структуре HTML-документа, который мы очищаем.
Чтобы получить текст первого тега, введите следующее:
soup.body.a.text # returns '1'
Чтобы получить заголовок в HTML теге body (обозначается классом «title»), введите в терминале следующее:
soup.body.p.b # returns Body's title
Для глубоко вложенных HTML-документов навигация может быстро стать утомительной. К счастью, Beautiful Soup поставляется с функцией поиска, поэтому нам не нужно перемещаться, чтобы получить элементы HTML.
