Парсер на Python не вытаскивает все данные. Модуль запросов
- Парсер на Python не вытаскивает все данные. Модуль запросов
- Как парсить сайты с автоподгрузкой. Как парсить контент, которого нет в коде страницы (контент подгружается скриптами в браузере)
- Парсинг динамических сайтов Python. Учимся парсить веб-сайты на Python + BeautifulSoup
- Динамический сайт на Python. Создание веб-приложений на Python с помощью Dash
Парсер на Python не вытаскивает все данные. Модуль запросов
Библиотека запросов используется для выполнения HTTP-запросов к определенному URL-адресу и возвращает ответ. Запросы Python предоставляют встроенные функции для управления как запросом, так и ответом.
Установка
Установка запросов зависит от типа операционной системы, основная команда в любом месте — открыть командный терминал и запустить,
pip install requests
Сделать запрос
Модуль запросов Python имеет несколько встроенных методов для выполнения HTTP-запросов к указанному URI с использованием запросов GET, POST, PUT, PATCH или HEAD. HTTP-запрос предназначен либо для получения данных из указанного URI, либо для отправки данных на сервер. Он работает как протокол запроса-ответа между клиентом и сервером. Здесь мы будем использовать запрос GET.
Метод GET используется для получения информации с заданного сервера с использованием заданного URI. Метод GET отправляет закодированную информацию о пользователе, добавленную к запросу страницы.
Пример: запросы Python, выполняющие запрос GET
Python3
importrequests
# Making a GET request
r=requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Вывод:
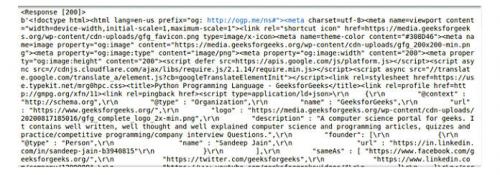
Объект ответа
Когда кто-то делает запрос к URI, он возвращает ответ. Этот объект Response в терминах python возвращается с помощью request.method (), являющегося методом — get, post, put и т.д. Response — это мощный объект с множеством функций и атрибутов, которые помогают в нормализации данных или создании идеальных частей кода. Например, response.status_code возвращает код состояния из самих заголовков, и можно проверить, был ли запрос обработан успешно или нет.
Объекты ответа могут использоваться для обозначения множества функций, методов и функций.
Как парсить сайты с автоподгрузкой. Как парсить контент, которого нет в коде страницы (контент подгружается скриптами в браузере)
Парсинг данных, которые подгружаюся POST запросом (парсинг с помощью макроса PHP_SCRIPT)
Когда вы открываете веб-страницу в браузере , например http://www.yandex.ru/, то происходит GET-запрос к этому адресу. Далее браузер получает текстовый контент по этому GET-запросу и начинает его обрабатывать (например, выполняет из кода документа скрипты, которые догружают WEB-страницу производя другие GET или POST запросы (для подгрузки дополнительного контента).
Если в Content Downloader использовать библиотеку Indy или Clever Internet Suite (ctrl+h для выбора библиотеки), то парсер не будет обрабатывать скрипты (произойдет обычный GET-запрос к URL-адресу). Но на некоторых интернет-сайтах такими скриптами могут подгружаться нужные нам данные, например, цены, описания товаров, ссылки и прочее. Зная url-адреса (ссылки), по которым происходят GET или POST Запросы для подгрузки нужных данных, мы можем подгружать эти данные при парсинге, используя макрос шаблона вывода(либо можно просто добавить эти адреса в список ссылок и производить парсинг с них).
Следует отметить, что при выборе библиотеки Internet Explorer (DOM) (WBApp) (включается в окне ctrl+h), код WEB-документов будет загружаться с использованием браузера Internet Explorer, который будет сам автоматически выполнять скрипты и подгружать дополнительный контент. Но выбор Internet Explorer снижает скорость парсинга и далее мы будем рассматривать варианты подгрузки данных без него. Также, этот метод позволяет запускать списки событий приложения WBApp, которые могут имитировать прокрутки WEB-страниц вниз, клики по различным элементам страниц и так далее… Подробнее о WBApp вы можете почитать.
Для того, чтобы узнать URL-адреса запросов подгрузки данных, мы будем использовать монитор сети браузера Firefox (shift+ctrl+e в браузере Firefox). Монитор сети будет отображать все GET и POST запросы, происходящие в браузере в реальном времени.
После получения данных о нужном запросе переходим к его воссозданию в Content Downloader.
Сначала определитесь, будет ли это запрос, по которому парсится основной контент или это запрос для подгрузки дополнительных данных к основному контенту.
Если это запрос, по которому вы берете основной контент, например, страницы с выдачей товаров заскриптованного сайта, то вставляйте адрес(а) запроса(ов) в список ссылок Content Downloader.
Если же это подгрузка дополнительных данных, например, описания товара или контактных данных, используйте для воссоздания запроса макрос шаблона вывода
Просто вставляете URL в список ссылок программы (F8) или генерируете список ссылок должным образом и настраиваете параметры запросов
Следует отметить, что библиотека Clever Internet Suite лучше работает с HTTP S
Подробнее о парсинге контента и ссылок с использованием POST-запросов
Подгрузка дополнительных данных (использование макроса GETMORECONTENT)
Если при парсинге вы будете использовать библиотеку Internet Explorer (DOM) (ctrl+h для смены библиотеки), то код документа будет браться из (созданного динамически) браузера (который загрузит указанную WEB-страницу, выполнит на ней все скрипты и подгрузит все данные). Минус этого метода состоит в том, что для загрузки каждого документа будет запускаться отдельный браузер Internet Explorer (очень ресурсоемкая процедура). Парсить таким методом можно максимум в 2 потока (иначе часть данных может просто не успевать догружаться). Также, этот метод позволяет запускать списки событий приложения WBApp, которые могут имитировать прокрутки WEB-страниц вниз, клики по различным элементам страниц и так далее… Подробнее о WBApp вы можете почитать тут .
Парсинг динамических сайтов Python. Учимся парсить веб-сайты на Python + BeautifulSoup
Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием(Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал:.
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.
Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4 . Их устанавливаем через терминал при помощи команд:
и
После чего пишем следующий код:
Тут мы импортируем новые библиотеки. URL это строка, она содержит ссылку на сайт. При помощи requests.get мы совершаем запрос к веб страничке. Сама функция возвращает ответ от сервера (200, 404 и т.д.), а page.content предоставляет нам полный код загруженной страницы. Тот же код, который мы видели в инспекторе.
Динамический сайт на Python. Создание веб-приложений на Python с помощью Dash
В настоящее время Dash можно загрузить, используя диспетчер пакетов Python, с помощью командыpip install dash. Dash распространяется с открытым исходным кодом и под лицензией MIT. Навы сможете ознакомиться с руководством по библиотеке, и на GitHub вы найдёте.
Dash — библиотека пользовательского интерфейса для создания аналитических веб-приложений. Она будет полезна для тех, кто использует Python для анализа и исследования данных, визуализации, моделирования и отчётности.
Dash значительно упрощает создание GUI (графических пользовательских интерфейсов) для анализа данных.приложения на Dash из 43 строк кода, который связывает выпадающее меню с графиком D3.js. Когда пользователь выбирает значение в выпадающем списке, код динамически экспортирует данные из Google Finance вDataFrame:
Код Dash является декларативным и реактивным, что упрощает создание сложных приложений, содержащих множество интерактивных элементов. Вот пример с 5 входными данными, 3 — выходными и с перекрёстной фильтрацией. Это приложение было написано на Python, и в нём всего лишь 160 строк кода:
Приложение на Dash с несколькими входными и выходными данным.
Для каждого элемента приложения можно задать собственные параметры размера, расположения, цвета и шрифта. Приложения на Dash создаются и публикуются в Сети, поэтому к ним можно применить всё, на что способен CSS. Ниже иллюстрируется пример тонко настраиваемого интерактивного приложения отчётности на Dash, выполненного в стиле отчёта финансовой организации Goldman Sachs.
Тонко настраиваемое приложение Dash, созданное в стиле отчёта финансовой организации Goldman Sachs.
Вам не нужно писать какой-либо код на JavaScript или HTML, когда ваше приложение на Dash запущено в веб-браузере. Dash предоставляет богатый набор интерактивных веб-компонентов.
import dash_core_components as dcc
dcc.Slider(value=4, min=-10, max=20, step=0.5,
labels={-5: '-5 Degrees', 0: '0', 10: '10 Degrees'})
Пример простого ползунка на Dash
Dash предоставляет простой реактивный декоратор для привязки вашего кода анализа данных к пользовательскому интерфейсу Dash.
@dash_app.callback(Output('graph-id', 'figure'),
)
def your_data_analysis_function(new_slider_value):
new_figure = your_compute_figure_function(new_slider_value)
return new_figure
Когда изменяется входной элемент (например, при выборе элемента в выпадающем списке или при передвижении ползунка), декоратор Dash предоставляет вашему коду Python новое входное значение.
Ваша функция Python может выполнять различные действия с новым входным значением: может фильтровать объектDataFrameбиблиотеки Pandas, выполнять SQL-запрос, запускать симуляцию, выполнять вычисления или запускать тестирование. Dash рассчитывает, что ваша функция вернёт новое свойство для какого-нибудь элемента пользовательского интерфейса, будь то новый график, новая таблица или новый текст.
В качестве примера ниже представлено приложение на Dash, которое обновляет текстовый элемент при взаимодействии с графиком. Код приложения фильтрует данные в PandasDataFrameна основе выбранной точки:
Приложение ниже отображает метаинформацию о лекарственных веществах при наведении курсора на точки в графике. Код приложения также добавляет строки в таблицу, когда появляются новые компоненты в выпадающем списке.
Благодаря этим двум разделениям между компонентами Python и реактивными функциональными декораторами, Dash разграничивает все технологии и протоколы, необходимые для создания интерактивного веб-приложения. Dash достаточно прост, чтобы привязать пользовательский интерфейс к коду Python за один вечер.