10 best Web Crawling tools & Software in 2023. Top 7 Web Crawler for Windows/Mac
- 10 best Web Crawling tools & Software in 2023. Top 7 Web Crawler for Windows/Mac
- Price Scraping tools. Why Price Data Scraping Not Easy
- Web Crawler online. Dexi.io
- Paid Web Scraping. How does Web Scraping Service Work?
- Best Web scraper chrome extension. Что такое парсинг?
- Free Web scraper. Best Free Web Scrapers 2023
- Web Crawler github. web-crawler
10 best Web Crawling tools & Software in 2023. Top 7 Web Crawler for Windows/Mac
Octoparse is a client-based web crawling tool to get web data into spreadsheets. With a user-friendly point-and-click interface, the software is specifically built for non-coders. Here is a video about Octoparse, also the main features and easy steps, so you can know it better.
Main features of Octoparse Web Crawler
- Scheduled cloud extraction: Extract dynamic data in real-time .
- Auto-detect mode: Get webpage data scraped automatically.
- Preset templates: Crawl data from popular websites within a few clicks.
- Bypass blocking: Cloud services and IP Proxy Servers to bypass ReCaptcha and blocking.
- Data cleaning: Built-in Regex and XPath configuration to get data cleaned automatically.
80legs is a powerful web crawling tool that can be configured based on customized requirements. It supports fetching huge amounts of data along with the option to download the extracted data instantly.
Main features of 80legs:
- API: 80legs offers API for users to create crawlers, manage data, and more.
- Scraper customization: 80legs’ JS-based app framework enables users to configure web crawls with customized behaviors.
- IP servers: A collection of IP addresses is used in web scraping requests.
Parsehub is a web crawler that collects data from websites using AJAX technology, JavaScript, cookies, etc. Its machine-learning technology can read, analyze and then transform web documents into relevant data.
Parsehub main features:
- Integration: Google Sheets, Tableau
- Data format: JSON, CSV
- Device: Mac, Windows, Linux
Besides the SaaS, VisualScraper offers web scraping services such as data delivery services and creating software extractors for clients. Visual Scraper enables users to schedule the projects to run at a specific time or repeat the sequence every minute, day, week, month, or year. Users could use it to extract news, updates, and forum frequently.
Important features for Visual Scraper:
- Various data formats: Excel, CSV, MS Access, MySQL, MSSQL, XML, or JSON.
- Seemingly the official website is not updating now and this information may not as up-to-date.
WebHarvy is a point-and-click web scraping software. It’s designed for non-programmers.
WebHarvy important features:
- Scrape Text, Images, URLs & Emails from websites.
- Data format: XML, CSV, JSON, or TSV file. Users can also export the scraped data to an SQL database.
Content Grabber is a web crawling software targeted at enterprises. It allows you to create stand-alone web crawling agents. Users are allowed to use C# or VB.NET to debug or write scripts to control the crawling process programming. It can extract content from almost any website and save it as structured data in a format of your choice.
Important features of Content Grabber:
- Integration with third-party data analytics or reporting applications.
- Powerful scripting editing, and debugging interfaces.
- Data formats: Excel reports, XML, CSV, and to most databases.
Helium Scraper is a visual web data crawling software for users to crawl web data. There is a 10-day trial available for new users to get started and once you are satisfied with how it works, with a one-time purchase you can use the software for a lifetime. Basically, it could satisfy users’ crawling needs at an elementary level.
H elium Scraper main features:
- Data format: Export data to CSV, Excel, XML, JSON, or SQLite.
- Fast extraction: Options to block images or unwanted web requests.
- Proxy rotation.
Price Scraping tools. Why Price Data Scraping Not Easy
However, we can’t scrape all the data with website APIs.
Some websites provide APIs for users to access part of their data. But even though these sites provide APIs, there still exist some data fields that we couldn’t scrape or have no authentication to access.
For example, Amazon provides a Product Advertising API, but the API itself couldn’t provide access to all the information displayed on its product page for people to scrape, like price and others. In this case, the only way to scrape more data, saying the price data field, is to build our own scraper by programming or using certain kinds of automated scraper tools.
It’s hard to scrape data, even for programmers.
Sometimes, even if we know how to scrape data on our own by programming, like using Ruby or Python, we still couldn’t scrape data successfully for various reasons. In most cases, we probably would be forbidden to scrape from certain websites due to our suspicious repeating scraping actions within a very short time. If so, we may need to utilize an IP proxy that automates IPs’ leaving without being traced by those target sites.
The possible solutions described above may require people to be familiar with coding skills and more advanced technical knowledge. Otherwise, it could be a tough or impossible task for us to complete.
To make scraping websites available for most people, I’d like to list several scraper tools that can help you scrape any commercial data, including price, stock, and reviews in a structured way with higher efficiency and much faster speed.
Web Crawler online. Dexi.io
Cloud Scraping Service in Dexi.io is designed for regular web users. It makes commitments to users in providing high-quality Cloud Service Scraping. It provides users with IP Proxy and in-built CAPTCHA resolving features that can help users scrape most websites.
Users can learn how to use CloudScrape by clicking and pointing easily, even for beginners. Cloud hosting makes it possible for all the scraped data to be stored in the Cloud. API allows monitoring and remote managing of web robots. Its CAPTCHA-solving option sets CloudScrape apart from services like Import.io or Kimono. The service provides a vast variety of data integrations so that extracted data might automatically be uploaded through (S)FTP or into your Google Drive, DropBox, Box, or AWS. The data integration can be completed seamlessly.
Disadvantages of online web crawlers
Apart from those free online web crawlers mentioned above, you can also find many other reliable web crawlers providing online service. However, they have some disadvantages, as the restrictions of cloud-based services, compare to desktop-based web scraping tools.
- Limited customizability: Many online web crawlers have limited customization options, which means you may not be able to tailor the crawler to fit your specific needs.
- Dependency on internet connection: Online web crawlers are entirely dependent on internet connectivity, which means if your connection is slow or unstable, the crawler’s performance may be affected.
- Limited control over the crawling process: Online web crawlers often have limited control over the crawling process, which could lead to incomplete or inaccurate data.
- Limited scalability: Some online web crawlers have limitations on the number of URLs that can be crawled or the volume of data that can be extracted, which could limit their scalability.
Paid Web Scraping. How does Web Scraping Service Work?
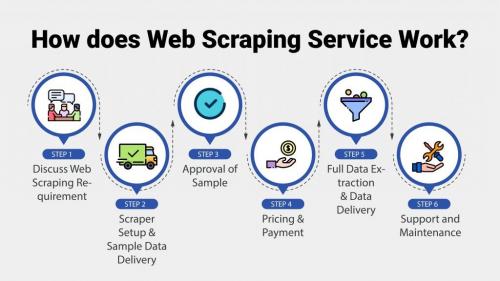
Before we go into the web scraping services, let’s understand the process of how a service works:
1. Discuss Web Scraping Requirement : It starts with an initial interaction and discussion regarding what your requirements are. This will help the service understand what you are looking for and serve you accordingly.
2. Scraper Setup & Sample Data Delivery : Based on your requirements, the service would build a sample scraper to extract the data you want. Once some of that data is scraped, the service would share the sample data with you for review. This will give you a sense of the quality and quantity of data you are likely to get.
3. Approval of Sample : Once you have seen and reviewed the data, you can give your feedback and suggestions, if any. Else, you can approve the sample and the service can move forward with extraction of the rest of the data you need.
4. Pricing & Payment : Once you approve the sample data and give a go-ahead for the full extraction of the data, it all comes down to pricing and payment. You need to work out the pricing and payment modalities with the service. This sort of seals the contract.
5. Full Data Extraction & Data Delivery : Now the service would rigorously work on the extraction of the data you need. Once the extraction is over, the service would deliver the data in the way discussed and agreed upon by the two parties.
6. Support and Maintenance : This is the part that takes care of the quality. The service would strive to provide clean and actionable data to you. At the same time, if there are any issues later, the service would also provide immediate and prompt customer support as well.
Discover How ProWebScraper Extracts Millions of Data Effortlessly
- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
Best Web scraper chrome extension. Что такое парсинг?
Парсинг — набор технологий и приемов для сбора общедоступных данных и хранения их в структурированном формате. Данные могут быть представлены множеством способов, таких как: текст, ссылки, содержимое ячеек в таблицах и так далее.
Чаще всего парсинг используется для мониторинга рыночных цен, предложений конкурентов, событий в новостных лентах, а также для составления базы данных потенциальных клиентов.
Выбор инструмента будет зависеть от множества факторов, но в первую очередь от объема добываемой информации и сложности противодействия защитным механизмам. Но всегда ли есть возможность или необходимость в привлечении специалистов? Всегда ли на сайтах встречается защита от парсинга? Может быть в каких-то случаях можно справиться самостоятельно?
Тогда что может быть сподручнее, чем всем привычный Google Chrome? !
Расширения для браузера — это хороший инструмент, если требуется собрать относительно небольшой набор данных. К тому же это рабочий способ протестировать сложность, доступность и осуществимость сбора нужных данных самостоятельно. Всё что потребуется — скачать понравившееся расширение и выбрать формат для накопления данных. Как правило это CSV (comma separated values — текстовый файл, где однотипные фрагменты разделены выбранным символом-разделителем, обычно запятой, отсюда и название) или привычные таблички Excel.
Ниже представлено сравнение десяти самых популярных расширений для Chrome.
Забегая вперед:
- все платные расширения имеют некоторый бесплатный период для ознакомления;
- только три — Instant Data Scraper, Spider и Scraper — полностью бесплатны;
- все платные инструменты (кроме Data Miner) имеют API (Application Program Interface — программный интерфейс, который позволяет настроить совместную работу с другими программами) .
Free Web scraper. Best Free Web Scrapers 2023
There are a lot of free web scraper tools and extensions designed specifically for non-programmers to help them extract and utilize the data for their business presence on the internet.
- Phantombuster – Winner!
- ScraperAPI
- Bright Data
- Apify
- Octoparse
- Import.io
- Dexi.io
- ScrapeHero Cloud (Browser-Based)
- OutWitHub (Browser Extension)
- Diffbot
Phantombuster is an excellent non-code cloud service for web scraping that you can try for free.
It is specifically designed for extracting data from social media and websites.
Phantombuster also helps in the collection of accurate and precise data for eCommerce stores.
Multiple APIs are present in this tool that can be used for extracting data in specified fields like real estate, Google Maps, and information collection from social networks.
Prominent Features
- Quick response time
- Simultaneous requests
- Can be useful for bulk data collection
- Great for social media
Although you can use this tool for free because there’s a trial, you’ll need to get a subscription when that free trial is up.
The price ranges vary and sometimes changes. It is a very quick tool and data is extracted straightaway.
Another excellent web scraping tool with a free trial, ScraperAPI is very famous among data scrapers.
This is one of the best tools available for web scraping and it tops the list because of its excellent and multiple features.
Prominent Features
- Rotation of IP address
- Data is available as JSON files
- Excellent cloud service to store data
- Webhooks and APIs for data incorporations
- You can automate and schedule data collection
- Also extract data from maps, graphs, and tables
If you are somebody who is hoping to find a free trial with a scraper that can help you with all your online scraping needs so that you don’t have to blow the budget, then you definitely need to check out Bright Data .
As well as being considered one of the best web scrapers in the industry, the fact that they are free means that you are going to be able to take your web scraping a long way, and you don’t have to worry about how much it is going to cost you.
You can either start straight away with them, or you can request a demo, so that you can really familiarize yourself with their features without having to compromise your finances.
Best Features
Bright Data offers a number of different features to its clients including their data collector, their search engine collector, and they also have proxy solutions as well.
They know how important it is to be able to pair up your free web scraping with a proxy, because the more you can protect yourself when you are implementing software like this online, the better off you’re going to be.
They have access to millions of residential and data center proxies, and they also have a data center and residential proxy manager, so that you can keep on top of what your proxies are doing, and you don’t have to worry about whether they are keeping you safe or not.
You can convert any web page into an API with the Apify web scraping tool that comes in both free and premium versions.
Along with a web scraper tool you can try for free, Apify can also provide you with the integration of several services and APIs (web integration) and help you automate workflows such as form filling (web automation).
Apify has several tools that help in the smooth and flawless extraction of data from multiple URLs.
Proxy – It helps you hide your identity while scraping web data. This makes web scraping perfectly smooth and safe.
Actors – It is a computing tool that allows easy developing, running, and sharing of multiple cloud services.
Multiple Output Options –Apify allows you to download the extracted data in Excel, JSON, SCSV, and database formats.
Web Crawler github. web-crawler
This is part of my big data analytics project.As part of this project, I am gathering students' reviews, comments and ratings of the schools where they have studied. Web crawler has been implemented to Crawl a website based on a search parameter, download webpages and perform ETL ( Extraction, Transform and Store) on data.
A web crawler is a program used to search through pages on the World Wide Web for documents containing a specific word, phrase, or topic. The purpose of implementing a web crawler in this program is the same. I want the crawler to search the website for the pages on the particular university that I am looking for. I derived the source code of web crawler from: https://code.google.com/p/crawler4j/ Crawler4j is an open source Java crawler which provides a simple interface to crawl a particular website. The program takes two input parameters: the root folder and the number of crawlers which are described below:
- Root folder: This is where the intermediate data is stored while the website is being crawled.
- Number of crawlers: Crawler4j supports multiple threads for crawling. This feature increases efficiency and time.
The program has two main pieces: the “crawler” and the “crawl controller”:
As part of my big data analytics project, I am gathering students' reviews, comments, and ratings of the schools where they have studied.
A web crawler has been implemented to crawl a website based on a search parameter, download webpages, and perform ETL (Extraction, Transform, and Store) on data.
A web crawler is a program used to search through pages on the World Wide Web for documents containing a specific word, phrase, or topic. The purpose of implementing a web crawler in this program is the same. I want the crawler to search the website for the pages on the particular university that I am looking for.
I derived the source code of web crawler from https://code.google.com/p/crawler4j/, Crawler4j is an open source Java crawler which provides a simple interface to crawl a particular website.
The program takes two input parameters: the root folder and the number of crawlers which are described below:
The Program
The program has two main pieces: the “crawler” and the “crawl controller”:
- Crawler: This is the main class that does the actual crawling. It is responsible for fetching and processing the web pages.
- Crawl Controller: This is the class that controls the crawling process. It is responsible for managing the crawlers and scheduling the crawling tasks.
- CrawlController: This program contains the main method. The crawl controller is responsible for setting up the configuration of the web crawler and creating an instance of a CrawlController that has configuration info. It also adds the seed to the CrawlController object to tell it where to start. When everything is setup, the CrawlController.start() method is called to start the crawling process. Here I set the controller parameters. Following is the list of those parameters: a) Politeness delay: This is the delay between each request sent to the website. This is done to avoid large volumes of requests to the server, which might lead to server crash or even blocking. The ideal value is 1 second. b) Maximum crawl depth: The default value is -1, which denotes unlimited depth. c) Maximum pages to fetch: The program can be set to restrict the number of pages to be fetched. Default value is -1, which denotes unlimited pages. d) Resume crawling: This option is used to set your crawl to be restarted (meaning that you can resume the crawl from a previously interrupted/crashed crawl). e) Seed URL: This is the URL from which the program should start crawling.