10 Best Web Scraping Tools of All Times. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
10 Best Web Scraping Tools of All Times. 2022 Top 10 Best Web Scraping Tools for Data Extraction | Web Scraping Tool | ScrapeStorm
14568 views
Abstract: This article will introduce the top10 best web scraping tools in 2019. They are ScrapeStorm, ScrapingHub, Import.io, Dexi.io, Diffbot, Mozenda, Parsehub, Webhose.io, Webharvy, Outwit. ScrapeStorm Free Download
Web scraping tools are designed to grab the information needed on the website. Such tools can save a lot of time for data extraction.
Here is a list of 10 recommended tools with better functionality and effectiveness.
1. ScrapeStorm
ScrapeStorm is an AI-Powered visual web scraping tool,which can be used to extract data from almost any websites without writing any code.
It is powerful and very easy to use. You only need to enter the URLs, it can intelligently identify the content and next page button, no complicated configuration, one-click scraping.
ScrapeStorm is a desktop app available for Windows, Mac, and Linux users. You can download the results in various formats including Excel, HTML, Txt and CSV. Moreover, you can export data to databases and websites.
Features:
1) Intelligent identification
2) IP Rotation and Verification Code Identification
3) Data Processing and Deduplication
4) File Download
5) Scheduled task
6) Automatic Export
8) Automatic Identification of E-commerce SKU and big images
Pros:
1) Easy to use
2) Fair price
3) Visual point and click operation
4) All systems supported
Cons:
No cloud services
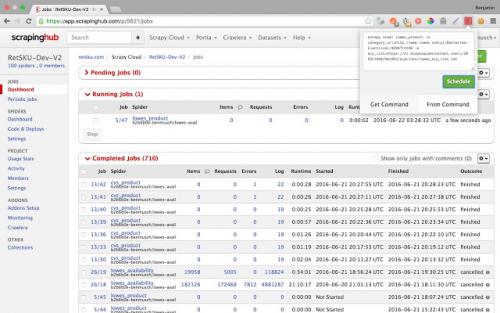
2.ScrapingHub
Scrapinghub is the developer-focused web scraping platform to offer several useful services to extract structured information from the Internet.
Scrapinghub has four major tools – Scrapy Cloud, Portia, Crawlera, and Splash.
Features:
1) Allows you to converts the entire web page into organized content
2) JS on-page support toggle
3) Handling Captchas
Pros:
1) Offer a collection of IP addresses covered more than 50 countries which is a solution for IP ban problems
2) The temporal charts were very useful
3) Handling login forms
4) The free plan retains extracted data in cloud for 7 days
Cons:
1) No Refunds
2) Not easy to use and needs to add many extensive add-ons
3) Can not process heavy sets of data
3.Import.io
Import.io is a platform which facilitates the conversion of semi-structured information in web pages into structured data, which can be used for anything from driving business decisions to integration with apps and other platforms.
They offer real-time data retrieval through their JSON REST-based and streaming APIs, and integration with many common programming languages and data analysis tools.
Features:
1) Point-and-click training
2) Automate web interaction and workflows
3) Easy Schedule data extraction
Pros:
1) Support almost every system
2) Nice clean interface and simple dashboard
3) No coding required
Cons:
1) Overpriced
2) Each sub-page costs credit
4.Dexi.io
Web Scraping & intelligent automation tool for professionals. Dexi.io is the most developed web scraping tool which enables businesses to extract and transform data from any web source through with leading automation and intelligent mining technology.
Dexi.io allows you to scrape or interact with data from any website with human precision. Advanced feature and APIs helps you transform and combine data into powerfull datasets or solutions.
Features:
1) Provide several integrations out of the box
2) Automatically de-duplicate data before sending it to your own systems.
Web Scraping python. Scrape and Parse Text From Websites
Collecting data from websites using an automated process is known as web scraping. Some websites explicitly forbid users from scraping their data with automated tools like the ones that you’ll create in this tutorial. Websites do this for two possible reasons:
- The site has a good reason to protect its data. For instance, Google Maps doesn’t let you request too many results too quickly.
- Making many repeated requests to a website’s server may use up bandwidth, slowing down the website for other users and potentially overloading the server such that the website stops responding entirely.
Before using your Python skills for web scraping, you should always check your target website’s acceptable use policy to see if accessing the website with automated tools is a violation of its terms of use. Legally, web scraping against the wishes of a website is very much a gray area.
Important: Please be aware that the following techniqueswhen used on websites that prohibit web scraping.
For this tutorial, you’ll use a page that’s hosted on Real Python’s server. The page that you’ll access has been set up for use with this tutorial.
Now that you’ve read the disclaimer, you can get to the fun stuff. In the next section, you’ll start grabbing all the HTML code from a single web page.
Build Your First Web Scraper
One useful package for web scraping that you can find in Python’s standard library isurllib, which contains tools for working with URLs. In particular, the urllib.request module contains a function calledurlopen()that you can use to open a URL within a program.
In IDLE’s interactive window, type the following to importurlopen():
The web page that you’ll open is at the following URL:
To open the web page, passurltourlopen():
urlopen()returns anHTTPResponseobject:
To extract the HTML from the page, first use theHTTPResponseobject’s.read()method, which returns a sequence of bytes. Then use.decode()to decode the bytes to a string using:
Now you can print the HTML to see the contents of the web page:
The output that you’re seeing is the HTML code of the website, which your browser renders when you visithttp://olympus.realpython.org/profiles/aphrodite:
Withurllib, you accessed the website similarly to how you would in your browser. However, instead of rendering the content visually, you grabbed the source code as text. Now that you have the HTML as text, you can extract information from it in a couple of different ways.
Web Scraping open source. Scrapy
Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format. One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large web scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use Scrapy.
Scrapy has a couple of handy built-in export formats such as JSON, XML, and CSV. Its built for extracting specific information from websites and allows you to focus on the data extraction using CSS selectors and choosing XPath expressions. Scraping web pages using Scrapy is much faster than other open source tools so its ideal for extensive large-scale scaping. It can also be used for a wide range of purposes, from data mining to monitoring and automated testing. What stands out about Scrapy is its ease of use and . If you are familiar with Python you’ll be up and running in just a couple of minutes. It runs on Linux, Mac OS, and Windows systems.Scrapy is under BSD license.
Web Scraping open source. Scrapy.
Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format.
One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large web scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use Scrapy.
Scrapy is under the BSD license.
Источник: https://lajfhak.ru-land.com/novosti/5-must-try-web-scraping-tools-what-web-scraping
Scrapy. Introducing Scrapy
A framework is a reusable, “semi-complete” application that can be specialized to produce custom applications. (Source: Johnson & Foote, 1988 )
In other words, the Scrapy framework provides a set of Python scripts that contain most of the code required to use Python for web scraping. We need only to add the last bit of code required to tell Python what pages to visit, what information to extract from those pages, and what to do with it. Scrapy also comes with a set of scripts to setup a new project and to control the scrapers that we will create.
It also means that Scrapy doesn’t work on its own. It requires a working Python installation (Python 2.7 and higher or 3.4 and higher - it should work in both Python 2 and 3), and a series of libraries to work. If you haven’t installed Python or Scrapy on your machine, you can refer to the setup instructions . If you install Scrapy as suggested there, it should take care to install all required libraries as well.
scrapy version
in a shell. If all is good, you should get the following back (as of February 2017):
Scrapy 2.1.0
If you have a newer version, you should be fine as well.
To introduce the use of Scrapy, we will reuse the same example we used in the previous section. We will start by scraping a list of URLs from the list of faculty of the Psychological & Brain Sciences and then visit those URLs to scrape detailed information about those faculty members.